Thoughts
I finally found a good, relatively concise, example of why I can't handle GEB.
So he's talking about similarities between the number-pairing used in Gödel's Theorem and the base-pairing used in DNA. If you don't remember, A (adenine) pairs with thymine (T), and guanine (G) pairs with cytosine (C), as described by F. Crick.
And at the end of the list where he talks about the conceptual similarities between numbers and DNA sequences, he points out that G (Gödel) pairs with C (Crick), and A (Arithmetization, a step in Gödel's proof) pairs with T (Translation, the step in interpretation of DNA).
And I'm like, what the hell. Is this a coincidence? Why point this out? Is this a joke, a pun? Did Hofstadter attribute the discovery of molecular biology to Crick, (as opposed to either of Crick's co-Nobel winners) for this joke? When Hofstadter coined the term "Arithmetization" 200 pages ago did he intentionally make it start with an A for this line? (Because the answer has to be yes, right?)
And there are bits like this throughout the entire book, every couple of pages, where Hofstadter just does an intellectual backflip because he can.
He creates a map of the Central Dogma of Molecular Biology and he calls it the "Central Dogmap."
He's like: "strand" backwards is DNA RTS, which could stand for "DNA rapid transit service" which is basically what RNA is.
But it's the "Arithmetization" that really gets me. Because he literally coined that term half a book ago.
Oh my fricking word I don't actually understand React. I've never made a "good" React app with cascading state.
I'm only at 2,066 total posts here. (A total of 59,508 words.) Still haven't overtaken my 5,000+ Tweets.
Updated per-season numbers. Unless I post like 10 times tomorrow, which I might, who knows, this is representative of the end of Fall 2021.
```
>>> [(p.formatted_name, p.get_all_entries().count()) for p in pagination.get_all_pages()]
[('Fall 2021', 379), ('Summer 2021', 375), ('Spring 2021', 317), ('Winter 2020', 410), ('Fall 2020', 584)]
```
How hard is it, really, to create a good natural language processing system? It seems like it shouldn't be that hard to create a parse tree
out of an English sentence, and then derive meaning from it.
So originally, I was planning on turning off pagination before Dec 1, when we start "Winter 2020." But I'm lazy and still long for change,
so I think we'll just roll with it. A fresh start, if you will.
I still kind of can't believe this website exists. Like, I just made it? And now it's here? Wild.
I suspect that there is overlap between people who program in assembly and speakers of toki pona.
@nateruessmusic’s background image on Twitter is a crop of the conspiracy theory pyramid, edited to include himself.
We’ve come a long way since 2006.
=> https://web.archive.org/web/20211024062747/https://blogs.tedneward.com/post/the-vietnam-of-computer-science/
This post is bad. I don’t want to be rude here, because it’s well written. And I don’t know what this guy’s credentials are. And I don’t know what the ORM scene in 2006 looked like. But come on:
> On top of this, we have a more subtle problem, that of the reliance on developers' dicipline: both the table name ("PERSON") and the column name in the criteria ("PERSON.LAST_NAME") are standard strings, taken as-is and fed to the system at runtime with no sort of validity-checking until then. This presents a classic problem in programming, that of the “fat-finger” error, where a developer doesn’t actually query the “PERSON” table, but the “PRESON” table instead.
How is this relevant to the claim that “Object-relation mapping is the Vietnam of computer science.” I guess there weren’t any scripting languages at the time and the thought of not having a compiler to validate your terms was awful. Like, I’ve only ever used an ORM in JS and Python. I don’t expect compile-time SQL errors. And that’s only one claim. Other “problems” include ‘what if you have two copies of the process running and one of them is paused by the OS and suspended to disk and the other process runs a database migration. Will your ORM save you then??’ Is there any solution to that problem? What the heck?
All of the issues are issues either with strict OOP (which is why I don’t write Java) or issues with having a database.
I almost forgot the part where he goes on about how the DB “instead is owned by another group within the company, typically the database administration (DBA) group.” And he acknowledges that this isn’t inherently an issue with the ORM, but still seems to think it’s relevant.
Reading, uh, *Without Bloodshed* I think, by ~starbreaker but not *Star Breaker*.
Anyways, he’s got this private army of vigilantes, obsessed with protecting people’s rights. It’s wild world-building. This person was arrested without being read their rights and the Adversaries broke them out of prison. But like, they also act as police sometimes.
> Adversaries talk a good game about due process, but if you hold office or wear a badge, their idea of proper procedure is to put a second round through your head―just to make sure.
For some reason, it’s easier for people to be passionate about content consumption than it is for them to be about content creation.
I don’t know what radio station I’m listening to but it just went from “Monday”, The Regrettes, to “We Are Young”, Fun. 10/10
Okay here's a spicy hot take:
The 40+ hour workweek worked fine decades ago because women largely didn't have jobs. Thanks to feminism and capitalism, there's now an expectation that both parents work full-time, which is not sustainable. The recent push for work-from-home is a result of this shift.
(I recognize that this is a simplification almost to absurdum. I may, to quote the About page, "immediately discard [this theory] as clearly worthless.")
I'm smarter than some people and not as smart as some people. And that's about the only interpersonal comparison to be made.
Communicating over public social media is boring. I want to talk through shared private Google docs and private Twitter accounts and IRC and
mailing lists and iMessage and Gemini.
Kind of jamming with my new AirPods Max. I'd never really used over-the-ear noise-cancelling headphones before.
Bill Wurtz's Questions is honestly one of the most beautiful websites on the internet, in my opinion.
*This Light*
"Common space continued to dissolve into private property, and our attention was pulled towards the monetized distraction of streaming content in solitude."
All the fricking "just use a subset of HTML" people do not understand how hard parsing HTML is.
You basically would have to say "any attribute is not allowed" and then allow clients to throw/abort on anything that had element attributes. I kind of want to try this now, and write a minimalistic HTML spec page, satirically. Like just make it 50,000 words listing all the things you're not allowed to do.
You would have to aim for "miniwebsites" that could be accessed by Chrome. But I really do not think you could design the spec in such a way that miniweb-browsers would be able to read any HTML pages that weren't designed for the miniweb. You couldn't have that as a design priority.
Wait frick HTML links are `a` elements that require an `href` attribute. So now you have to support attributes. Like show me a regular expression that can hope to parse a single HTML element.
Okay, okay, you probably don't follow. For an example, given `<a href="..." tabindex=0>Click me</a>` is pretty common. See the problem? Even if we can parse attributes, a naive attribute parsing approach assumes the attribute is surrounded by quotes. But quotes are optional. And if you don't have quotes, it's hellish to find where the attribute parameter ends. Oh not to mention a lot of the time you don't have an `=` at all.
I've said before, I still don't understand the rules by which HTML collapses whitespace.
HTML and Gemtext are just not in the same galaxy. It's like walking into a conversation about markdown and saying "why not just use HTML". Except that HTML is still HTML and Gemtext is about an order of magnitude easier to parse than Markdown. Like, no one knows how to parse Markdown.
If you asked me to write a Gemtext parser in assembly, I'd be like, 'yeah sure why not.' If you asked me to write a parser for a *subset* of HTML in assembly, I'd tell you it wasn't possible. Like, okay, you'd have to say that you're not allowed to nest elements. (Because otherwise I have to come up with dynamic memory structures to store my theoretically infinite nested parse tree...) No attributes except for `href`, no elements except for `a`, `h1…6`, `pre`, `block quote`, wait! But if we have bulleted lists, then we have to nest elements. That's awful.
Like, imagine you have a feature-set, say, the stuff gemtext supports. And you want to be able to store and parse those features. Option 1, is all of the complexity of parsing HTML. Option 2 is literally designed to be as simple as possible to parse while support the needed features.
I haven't even gotten to servers. Chrome sends so fricking many headers, you'd need a dynamic memory system in order to handle an arbitrary number of headers. Modern browser could add more headers at any time. Firefox just invented the DNT header and started sending it. There's no way around the complexity and extensibility of the web.
Gemini is designed for non-extensibility. So you can write a server in assembly and allocate 1024 bytes for the URL and know that you'll never need more than that. Fun weekend project, Gemini server in assembly. It would be better than Astronomical Theater.
Mailing the Gemini mailing list at 2 am. I've never interacted with a mailing list before. What could go wrong?
Hacker News comments are so bad. I’m going to stop commenting there, I’m done.
German PHD student describes a thought experiment in which you have infinite money and are incapable of telling if you’re sick. If you have 2 doctors, who can tell if you’re sick, but don’t care about your personal well-being, how do you pay them? (Ex. Pay them both only if they agree; pay one for diagnosis, one for treatment; etc.) It’s a game theory problem, with implications for negotiating with hyper-intelligent AI or aliens.
The comments:
‘Only pay the doctors if you’re healthy’
‘I am a doctor and I just want to help people’
‘Move to a country with a great healthcare system like Sweden’
‘I’m not going to read the article, the premise is flawed’
Honestly these comments are so bad. Comments that understand that this is a metaphor and not a commentary on US Healthcare are the minority. This is Tumblr levels of reading comprehension.
=> https://news.ycombinator.com/item?id=29269973

CLI tools auto-opening applications, including other shells, is extremely annoying.
The react native CLI will open Terminal.app in order to run a build service server, before then opening the iOS simulator.
Also throwback to the last time I used React Native.

I fixed it. I had set $EDITOR to `vim` so zsh of course stopped answering to emacs keybindings.
OOoooohhh my word.
I don't trust anyone.
I don't want to see a therapist because I'm afraid.
I'm conflicted and I don't want to unravel my feelings because I'm afraid. I don't know what I'm afraid of. Rejection, I guess. Being known? Any of it? The unknown? People.
Maybe there's nothing there to untangle and I actually just have an irrational social anxiety that I just need to ignore, not understand.
I suspect that I move in cycles with the weather, but there is an insufficient evidence to prove that.
"How Do You Love?"
"I know the question that is foremost in your thoughts. Who ate the babies?"
-Synopsis for Latecomers, They Might be Giants
To elaborate on that last Thought. A ‘normal’ social anxiety would be ‘I have to try to be normal.’ But the second level to recognize is
that there’s an implicit assumption a) that I am different, and b) that’s a bad thing.
And that’s not black and white—it’s a discussion question, not a yes/no question. But it’s important to deal with all of those questions.
I'm afraid of other people. Like, obviously in a superficial way, but also in a deeper way. Where I assume that other people are different.
I didn't go to church Sunday and now I'm regretting it.
The weekend is an important time for me to recover sanity and it's all too easy for me to allow myself to be overcome by insanity over the weekend—since I don't need to be sane over the weekend. But if I do that, then I don't have the sanity to make it through the week.
.
The sky is shattered like a jigsaw puzzle.
Fragments of it fall between my ears.
Fragments of it float overhead.
The light from the sun shines down.
The leaves fall aimlessly.
Buildings slice the world.
I'm on the ground.
The sky above.
Grass below.
Me.
My problem with fan fiction is that it doesn’t exist for the media I want. I can search AO3 for anything and all I get is Harry Potter
I've commented before on how great the Vötgil episode [0] of Conlang Critic is [1]. But Misali doesn't let it go and keeps bringing it up as
a bad example in other episodes of Conlang Critic. Episode 4 [2] they roast this 1980s feminist for not being inclusive of non-binary people and then finish the episode with 'but that's not as bad as Vötgil which has no redeeming qualities.'
Also BöpGil [3] is a bop please listen to it.
[0]: See [1]
[1]: https://thoughts.learnerpages.com/?show=b77f1767-6ec4-44b8-aedd-6b75338ce7f4
[2]: I'm too lazy to actually find links, look it up or something.
[3]: https://youtu.be/MNVKuDGX7qY
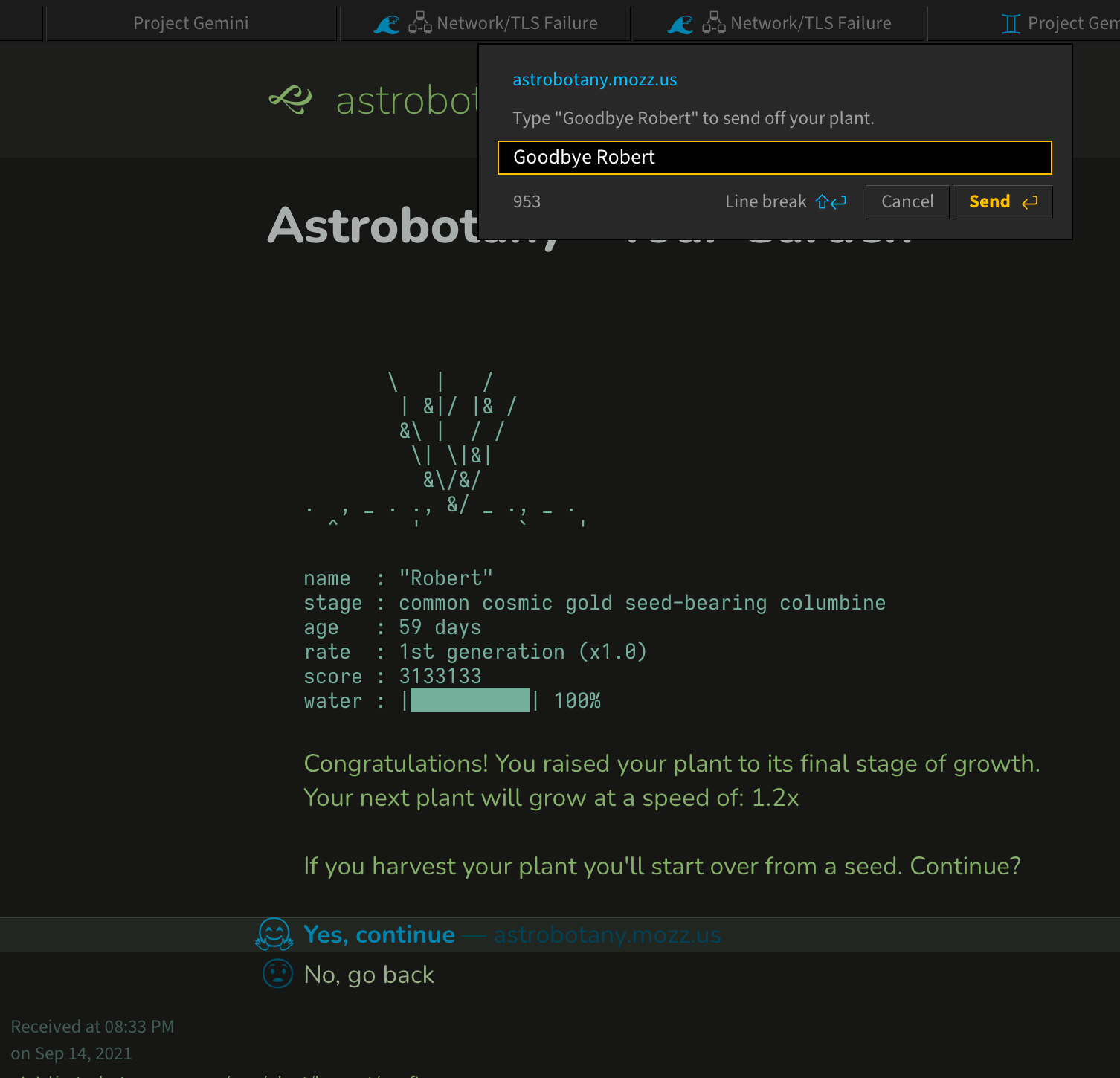
I finished the book. Took me about 10 hours from start to finish. I don’t think I ate dinner. Help
Reading the *Left-handed Booksellers of London*, by Nix. And he keeps dropping these references. And I miss most of them.
Some of the references are to Tolkien or Lewis or whatever. But then I catch like a line from a Donne poem I memorized once, just as a part of dialogue. Like, the character says "One short sleep past, we wake eternally," and the conversation moves on. That's a direct quote from a poem from over 400 years ago.
The thing that gets me is that there are lots of other lines in the book that I think could be references to something, that go over my head.
One of the characters drops 2 lines of the Major General's patter. Like…
I always thought that scene in *Dead Poets Society* where they stand on the desks was symbolic, but I just stood on my desk and the room
actually looks different.
I enjoy playing with space and geometry.
I need variety in my life so the light theme looks like this now.
Color picked from an American Animals (2018) poster. I haven't seen the movie but man that promo art is an aesthetic.
Thinking about the time I had "INTJ" in my Khan Academy nickname. Humans like labels.
I think that's one of the reasons I obsess with my name. I introduce myself and describe myself with "I am Matthias" not just as an introduction, but as a descriptor. "Matthias" is by far the most accurate label I have found for myself.
I would argue, counter intuitively, that positive feedback hurts an action that is an expectation.
That is to say, if someone is regularly doing something, rewarding them for doing it makes them less likely to continue.
I forgot Chance featured Death Cab, I’m crying.
If Ryan Met ever remixed Death Cab I would probably die.
Posting this one from Arch Linux. With my own keyboard. That's right ladies, we're back in business.
I'm posting this from macOS recovery mode. It could be fun to use Safari in recovery mode as a minimalistic OS.
Althought it seems less performant, not more. And there are some rough edges. Something something simplicity inside a complex system.
I'm totally going to end up watching TFC aren't I. He just hit 100k subs, so that's pretty neat.
I’m floating. I can’t bring myself to dive back down. I’m afraid not of the water, but of drowning.
Decided I'm not going to shut this site down, since it's cool. But I might have to pivot the content. Might start posting poetry or bits of
story of something.
The problem with any adaptation of the Count of Monte Cristo's character is that you end up making him more sane.
He's honestly a Joker-level character sometimes.
> “Then," continued Chateau-Renaud, "since you have an establishment, a steward, and a hotel in the Champs Elysees, you only want a mistress.”
> “I have something better than that," said Monte Cristo; "I have a slave. You procure your mistresses from the opera, the Vaudeville, or the Varietes; I purchased mine at Constantinople; it cost me more, but I have nothing to fear.”
> “But you forget," replied Debray, laughing, "that we are Franks by name and franks by nature, as King Charles said, and that the moment she puts her foot in France your slave becomes free.”
> “Who will tell her?”
> “The first person who sees her.”
> “She only speaks Romaic.”
And it's these interactions that end up getting cut in any abridged version or adaptation. Because honestly what the hell.
Although if I remember correctly, I think later the Count tells his slave that she's free, and she chooses to stay with him, and the Count admits that he views her like a daughter and isn't sleeping with her and she speaks French and the Count is actually making 4D chess moves that no one else (including me) understands.
Thinking about shutting this site down. It's not obvious that it helps me anymore.
Originally, it helped me get rid of intrusive thoughts by posting them here. But now I find myself making an effort to remember things that I would otherwise forget, just in order to post them here.
Are you a Conlang Critic jan Misali fan, or a “Wario Faces Consequences for His Actions” jan Misali fan?
Just moved all my sites over to Apache Managed Domain from certbot, since I was using a version of certbot from at least 2 years ago.
Certbot had also stopped working for some reason.
Now I just have to figure out how to uninstall certbot. Can't be that hard, right?
I love people who leave 1-2 star Goodread reviews on books I read as a kid. Like, I get it, this piece of children's literature is not up to
your standards. I'm sure your criticisms are valid but it's too late; I already read it and enjoyed it.
"Just reading about how the zeppelins are constructed or how to operate an airship made out of a combination of creatures bored me to death." I'm sorry that you didn't enjoy the description of the giant flying steampunk whale but that is all I want in a book, thank you.
Oh my work, oh my fricking word. I just love reading fiction so much. I just absolutely guzzle fiction, it's incredible.
I'm not quite sure when, but at some point I just learned how to use `git`. Like just through trial-and-error I guess. I just cherry-picked
a commit from one repo onto another. And like, I'm not a git expert. There could have been a better way to do what I wanted. But I managed to do it what I wanted first-try, no errors. Which I'm pretty impressed with.
I think maybe time was meant to be linear and things were meant to be ephemeral. Maybe holding on to the past is a mistake.
It's interesting to me that my bottleneck in being able to post audio samples here is the number of things I think are worth recording, not
my time or willingness to record myself.
Interestingly, I think I've created some of my best art at times I wasn't trying to. When I was making games on KA, I viewed myself as a
player of games, and set out to make the type of game that I wanted to play. Similarly, some of the books that I've previously started, I began the type of book that I wanted to read. But those mindsets are very different from the artist's mindset. When I set out to create art I get carried away with the creative freedom of it all. And if I succeed in capturing my emotion or my vision, as I did on the About page here for instance, I end up with something that at the very least is so different from other things that no one knows that they want it.
“alone” — inquiry
=> gemini://midnight.pub/posts/687
Transcript
“Oh, so good / yet not understood by many, if any, others / so one more shot / one more smoke / he waited”
Programmers are generally anxious.
I think it’s something about debugging that encourages you to question everything. But it may also be something about the logical nature of programming itself. Anyways, programmers like guarantees, things that don’t change, and rigorously defined behavior. Not only does that structure make us comfortable, the lack of structure scares us.
My pride in large part staves off depression, etc, but doesn’t do much against the insistence of my social anxiety that no one likes me.
Thinking about whether I can go live with the Amish. Like, do they want me? Or would they kick me out?
Does anyone want me?
It’s interesting, because I think it’s pretty clear that my current mindset is unsustainable. But I am less willing to reinvent myself,
really, than I was 4.3 years ago when I invited Matthias 2.0. Matthias 1.0 had ambition, and that ambition allowed him to change into Matthias 2.0 in an attempt to better satisfy those ambitions. But somehow the ambition didn’t get carried over, or something. (I’m not currently Matthias 2.0, btw. Matthias 2.0 worked well for a little while, although in retrospect there was foreshadowing of future problems. But somehow it broke down, around 1.7–2.6 years ago, and now we’re here. Also, some numbering schemes start at different places, this Thought defines Matthias 1.0 as starting 11 years ago.)
I realized earlier today that I would rather be around people who insult me than people who compliment me because I can trust that the
former is being honest.
Who hurt me as a kid? I don't trust anyone.
I don't love the About page, in that it represents a time in my life that has passed. It no longer resinates with me in the way that it did
when I wrote it. But am very happy with it and proud of it because it is a long, and written in a consistent tone, and I think it captures the tone of this site overall.
I was logged into my gmail account watching an English Youtube video, and Google shows me an ad for some Pixel phone, in Spanish!
I still plan on open-sourcing this at some point, but I have secret keys in version control and text on the About page.
I’m leaning towards CC0, but I don’t want to public domain my writing.
It’s interesting to think about how there are no rules to the content I could post here, except for the minimum enforced by the government
The cookie banner on nature.com is literally larger than the anti-nicotine warning on a vape store. How did we get here?
"Perhaps 'tis the mental difference between embracing and eschewing moments?"
Transcript
Perhaps 'tis the mental difference between embracing and eschewing moments?
It's possible TFC just has no fricking idea how big HermitCraft is. Like IRL he could just not know.
All languages should have a `constrain` function somewhere in their standard library.
It's simple enough that I should be able to use it in one line, but `min(max_val, max(min_val, val))` is ugly and unreadable.
This website does not work in SerenityOS browser. I think it doesn't support background color, so the text is all white-on-white.
Accidentally bought small face masks. (I didn't realize face masks came in different sizes.) My head is waaaay to big for this.
"You're never going to be able to make something safe. You can increase the margin of safety. And as long as you're holding to that, and you
don't suffer the illusion that you have made something safe, then you stay in that mental state that allows you to deal with contingencies, cause they're going to happen."
-Adam Savage
.
Transcript
"When it's quiet and I stop thinking, I hear voices in my head that sound like radio commercials."
"When it's quiet and I stop thinking, I hear voices in my head that sound like radio commercials."
I wish I could climb out my window, but the next best thing is walking out my door.
(My window is very far off of the ground. I totally would if I could, trust me.)
Promises are so fricking opinionated. I can't. Javascript is so un-opinionated and then, Promises
Just found out that "nickelodeon" was a slang term for a jukebox, from *GEB*. I feel like I've aged 10 years.
I don't like fuzzy finds or command palettes or quick switchers or etc. But I don't know why, because I like the idea and I will use them...
It's a miracle any code works.
We are constructing a tower of Babel and God can allow it to stand because it will fall to our own hubris.
This is about the codebase that is shared between my Gemini server and my website.
There are hundreds of things I could do in this moment and I don't know which ones are important or which ones I want to do.
I really want to put like a dumb CRT-effect overlay over this website but my GPU (or lack thereof) cannot handle it.
Some follow-up, I found "The Last Person in America Not Online"
I posted May 15th (https://thoughts.learnerpages.com/?show=cf045c64-f54f-423f-b682-52b99c7294d2), “You May Be Looking At The Last Person In America Not Online.” And then on May 30th (https://thoughts.learnerpages.com/?show=4ade4aea-3914-4605-bb6d-40dbfba63b77) I commented that I didn't remember where that had come from. Well, I searched for it again, and this time Google gave me this reddit post: https://www.reddit.com/r/mac/comments/nd1cbl/just_a_bit_of_dust/, (an image of an AOL disk with a reflective surface under the words.)
Just a bit of closure.
I’ve decided mixing wet and dry ingredients separately is a superstition invented by people with surplus mixing bowls.
The thing about *Thinking Fast and Slow* that makes it so interesting, is that’s not a list of ways that humans are illogical and tips on
how to be more logical—although it certainly appears to be at times. But what it ends up doing is thoroughly tearing down the myth that humans are rational at all.
My Twitter data log has every time I've logged into Twitter and the IP address.
Edit: Not accesses, logins, I think
Some have said that society is an illusion. But it is more precise to say that society is a series of illusions stacked on top of each other
'Woah the Matlab `plot` syntax is *exactly* like Matplotlib!'
Where do you think the "mat" in "matplotlib" comes from, exactly??
I believe I once promised someone, if only myself, that this website would concentrate my insanity and allow me to be more sane elsewhere.
That was a falsehood.
Has anyone done Programming Language Critic? The show that gets facts wrong about your favorite programming language?
Looks like there are a couple of surprisingly high quality Youtube channels doing esolang reviews. But that's surprisingly high quality given their low popularity, not like, actually good and definitely not at the level of jan Misali.
Okay back to the seasons, I'm not vibing with them. It feels really disorienting and doesn't really give you a sense of scale. Like, how far
back is this? Is this from 10 years ago or yesterday? I wonder if that's just because I made the site? Because when I'm looking back on Hacker News, for example, it feels almost creepy, like walking through a ghost town or archives, reading comments from years ago. I don't get that same feeling here.
On the other hand, that's probably fine.
The functionality of this site was obviously inspired by Twitter, but a lot of the feel and aesthetic of the this site was inspired by bill wurtz's "questions". https://billwurtz.com/questions/questions.html I just opened "questions" again, and started reading, and was struck by how timeless everything was. I looked at the timestamps, but like I'm tired and I don't want to try to figure out how long ago any of them were posted. And it doesn't matter.
So in that sense, I wouldn't be unhappy if everything here was timeless and you could jump into the middle. (Like you can with XKCD for example.)
Now, I don't want this site to be confusing to navigate, like billwurtz.com. I do want you to be able to come to this site and immediately get a feel for "oh he's posted several times a day for a year…" Maybe numbered pages? e.g. 1-500, 500-1000, etc? I think that works well for XKCD.
There are a lot of reasons that I don't always want to allow comments on posts here, but one of them is that I extensively use "help" and
rhetorical questions, that I don't mean as genuine. See for example the last post. I'm transcribing the questions that are running through my own head, not asking you these questions.
I can't.
Okay so you need context probably. I have fancy textboxes on the post page here that get taller when you type in them.
Well, the trigger for them expanding is dependent on whether or not I have a mouse plugged in. I don't want to get into all of it, something something, macOS displays scrollbars, etc. Is this a web problem? Can I blame this on the W3? Or this is a problem with software in general? Should I fix this? Can I fix this? Help.
I'm trying to post here more often after I did the per-quarter breakdown and realized how much I posted the first season of this site.
I still haven't solved formatting/markdown. I'm doing client side markdown ! I've been thinking about it for months.
I'm so glad I left Twitter. I've heard Twitter doesn't let you Tweet the exact same thing twice and it's stressful for me to wonder
"have I posted this before?"
There's a bit of Marxist theory that one of the pains of capitalism is that it separates the laborer from the product of their labor.
The concrete example is the assembly line worker that feels no passion for their job, and Marx attributes this to them not being able to take responsibility for the product that rolls off of the assembly line. I think this is only one symptom of a larger phenomena of corporate capitalism. Corporations are, in a sense, magical things because they are more than the sum of their parts. This shows up in other places, but in this example, no one at the corporation is passionate about making whatever product they are making. And yet, the corporation as a whole appears to have motives, which don't align with the motives of any of its members. This can be a good thing, sometimes. The communist commune model of "everyone does what they're passionate about" doesn't work in practice or at scale. But it's interesting to think about.
Javascript is extremely flexible and I know it very well. It doesn't make much sense for me to do anything but double down on using it.
Here's a Thought from last year that talks about pagination
=> https://thoughts.learnerpages.com/?show=b3b9020f-edbd-412d-9787-6874b21622d1
I'm experimenting with pagination. Right now I'm grouping Thoughts by meteorological season. Each page is still absurdly long (good), while
dropping the amount of text transferred to ~1/10 (good). The (bad) is that I now have a row of buttons and multiple pages. Which adds a significant amount of mental complexity.
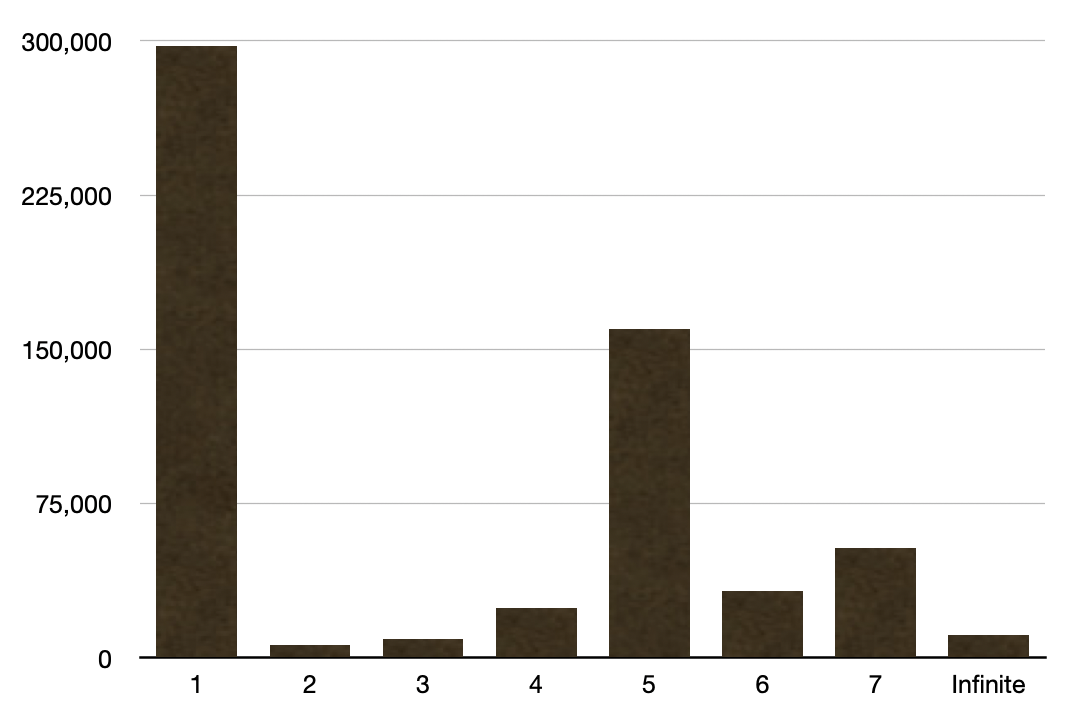
I'm at 1,842 Thoughts, broken down as (per-season)
```py
[('Fall 2021', 156), ('Summer 2021', 375), ('Spring 2021', 317), ('Winter 2020', 410), ('Fall 2020', 584)]
```
I think the 300-500 thoughts/page range is about where I want to be, but it looks like I'm still seeing flashes of unformatted content due to JS markdown. Which I was hoping this would fix. I really need to move to server-side rendering.
The other bad, of course, is that when we roll over to winter in a month, the front page will drop to 0 posts at some point. Which is not exactly the aesthetic that I'm going for.
Also added a permalink button so you can find thoughts buried in the archives, but I'm not super happy with it. It will probably change.
I once said "I don't have trouble focusing, focusing just feels weird" [1]. I certainly find it a lot easier to switch between tasks every 5
minutes that it is to work on one task for too long.
=> /?show=65a832f0-c86e-4595-89af-6dd25eb8f67d [1]
I think it's interesting to keep in mind that any project can be acquired by big corporate at any time. Keybase, NPM, Audacity, etc.
So I started this website because I got addicted to the dopamine hit associated with someone liking my Tweets, right.
Well, the lack of exposure hasn't made me any better at handling it. I started a one-off Instagram account, and I just got 2 followers, and my heart is racing.
I want to make this website weirder, but one of things that makes this website so weird right now is its simplicity. If I added some gimmic,
I could lose simplicity, resulting in a net zero change in weirdness and a net negative in website quality.
"Your generosity so far also matches exactly an adversaries likely plan to entrap me."
(Spoiler, it was actually an adversary entrapping him. Too late.)
Another example of things that actually happened, but would never be believable in fiction.
The thing that frustrates me about Jekyll is that it forces content into the _data and _posts directories. So if you try to group all of
your content together, then all of your content, everything you regularly change, is in sub-directories with names that start with `_`.
But like, you don't have to do that. Jekyll will also post-process files in a `./posts` directory. And this is the type of thing that gets me about every static site generator (or least Hugo and Jekyll and eleventy). They have these conventions and assumptions about where to put their files, but it's unclear which of them are defaults and which of them are enforced. And how easy it is to overwrite any given default.

I focus on listening a lot. But if you're looking for information, asking a good question can be as important of a skill as listening.
=> https://drewdevault.com/2020/03/18/Reckless-limitless-scope.html The reckless, infinite scope of web browsers
I don't like Drew DeVault. But he recognizes the issues with the web that many people do not.
In the past two days, Facebook has gone down, all of Twitch's source was leaked, and all `.club` domains went down. This is anarchy.
=> https://xkcd.com/267/ XKCD 267
Transcript
I shouldn't do this, but I pulled you out for a moment to give you a hint.
Take wrong turns. Talk to strangers. Open unmarked doors. And if you see a group of people in a field, go find out what they're doing. Do things without always knowing how they'll turn out.
You're curious and smart and bored, and all you see is the choice between working hard and slacking off. There are so many adventures that you miss because you're waiting to think of a plan. To find them, look for tiny interesting choices. And remember that you are always making up the future as you go.
Figured out you can move the address bar back to the top of the screen in iOS 15
From the aA, Show Top Tab Bar
"owning a computer to survive/participate in society is a consequence of capitalism"
Should I stop posting bad socialist takes here? This one is so out there I can't even provide commentary.
I'm such a perfectionist. I sometimes say, if it's worth doing it's worth doing better than anyone else. But even that isn't enough to
satisfy me.
This website is one of the things I'm proud of, that brings my joy to use. But even with this, I have a 25 item to-do list, 3 posts with errors that need editing, and 7 grammar mistakes on the About page. (25 item todo list doesn't sound like a lot, but start thinking about it. How many bugs or missing features can you name for this site? I can name 25.)
This is a cry for help.
We're going to run out of IPv6 addresses because we're using them to encode data. Facebook's IPv6 address is 2a03:2880:f0fc:c:face:b00c:0:35
"face:b00c"
If the pandemic isn't over by, say, 2030, I'm going to stop wearing a mask, tetra variant or no.
I once read an interesting excerpt from *Being Alive*, by Tim Ingold (p. 36). In it he points out the degree to which we constrain the role of our feet, and moreover, how this is regarded as a mark of how civilized we are as a society.
> Paradoxically, it seems that with the onward march of civilisation, the foot has been progressively *withdrawn* from the sphere of operation of the intellect, that it has regressed to the status of a merely mechanical apparatus, and moreover that this development is a consequence — not a cause — of technical advance in footwear. Boots and shoes, products of the ever more versatile human hand, imprison the foot, constricting its freedom of movement and blunting its sense of touch.
At the risk of over-extrapolating, I would not be surprised if, in 8 years, it is socially expected that everyone remain masked when possible. Not out of a particular fear, as today, but out of respect. "Mouth-breather" is already an insult, and chewing with your mouth open is already rude. Is it really that much of a jump to expect people to cover their mouths with cloth as often as possible?
This mask-wearing would be used as evidence of the advances of civilization, in the same way that wearing shoes is, but it is unclear whether it would be tangibly beneficial. Eradication of some airborne illness is near the bottom of my goals for human progress, far after eradicating hunger, poverty, space travel etc. Many, however, would take this objection without issue.
Why is this a problem? Because wearing a mask drastically reduces our sense of smell. Smell is one of only 4 senses that can really be used to experience the world around us. (The sense of smell is most important outdoors. It's possible, in a projected future, that masking outside is seen as unnecessary. It's also possible that we develop masks that you can smell through, etc.)
But the sense of smell, in modern civilization, isn't valued. Moving your nose to better smell something is an extremely undignified act. Dogs smell things, humans don't. (We praise dogs for their sense of smell, but dogs are unashamed to put their noses to the ground. I've tried it, you can smell a lot more with your face in the grass. I was also immediately scoffed.)
The sense of smell is often neglected, but it still plays an important role in experiencing the world around us.
The nose and mouth are not significantly valued in western culture today. If they were to be blunted or obscured by a mask, most people would not realize the magnitude of what would be lost. It is important to me that I get the fullest possible experience of the world God created, bar of course urgent public-health crises. If mask wearing is still the social norm in 9 years, I think it reasonable to say at that point that this is not a short-term public heath crisis, and is in fact a cultural and value shift. This value shift would be one that I protest.
jan Misali just roasts a language for 10 minutes in the most dry tone. It's amazing.
"It's not very computer friendly, which wouldn't be a problem if it were pen and paper friendly, which it isn't."
=> https://youtu.be/12bT6wGXESc
I don't even care about conlangs at all. He's been doing this for 5 years.
I've been using Atom for the past couple weeks. I just opened IntelliJ. It's so painful
The package is called `python-decouple` and is listed in the requirements.txt as such. IntelliJ can't seem to fathom that.

Made this earlier, inspired by a Reddit comment
(Did you notice this image has `alt` text? Big things are always happening behind the scenes here.)

I watched *October Sky* with some friends yesterday to celebrate the start of October. It's a very good movie.
I want to know what the people who make static site generators are thinking. Because I think about static sites a lot. And none of the
static site generators are intuitive to me. They're all weird.
I'm tired of popups. If I open the front page of your website, and I get hit with a popup, I'm leaving. I don't care about your cookies or
your newsletter or donating now or anything except the content I came to see.
I don't get it. I have voluntarily opened your website because I want to see your content. Do you know how hard that is? I've given you that hard-to-get initial click, and you respond with a full-screen cookie popup? Please.
Yeah so a bee stung me on the lip this morning while I was biking. I just biked into it face-first and it stung me.
I kind of can't beelieve it happened. My lip still hurts a bit. I got stung by a bee, right on the lip.
I feel like Oscar from VeggieTale's "I Love My Lips." Usta!
My pain tolerance is so low. I have been completely incapacitated by a bee sting for the last 2 hours.
Cloudflare's R2 seems super exciting because it's super cheap, but like, I don't even know what I would do with unlimited download.
I got mail. It’s a handwritten note from the Democratic Party. I can’t read what it says because it’s in cursive. I hate 2021.
Okay the nuclear siren ambient noise actually isn't that bad.
=> https://neal.fun/ambient-chaos/
Good morning. Reddit is so radically left-wing, it’s kind of shocking to me. It’s kind of a cult.
It's shocking to me how lightweight Debian seems to be, considering that that's not one of the projects stated goals at all.
A Docker container's lack of persistence really isn't appealing to me, but I do appreciate the super quick start times.
It's really nice to be able to `docker run -it alpine /bin/sh` without having to download or flash Alpine or anything.
"But the fact is I would not have spent a decade doing this, if I did not believe I was at least tiny bit ridiculously filthy at it"
-Don't Be Nice, Watsky
How frequently should a code-base be rewritten in order to be considered healthy and active? Ever?
Allow me to propose a security model called, 'don't have anything anyone would want to attack.'
The Gemini protocol is using this model with great success.
Swift has all these really cool language features that are like "Woah" but they're kind of solutions without a problem.
Like, they have "trailing closures" so if you have a function `setTimeout(action: () -> Void)` you can call it
```swift
setTimeout(action: {
print("Hello")
})
```
Or, you can use a trailing closure and call it like
```
setTimeout() {
print("hello")
}
```
Like, would I use that? Absolutely. Would I miss it if it wasn't there? Probably not.
The parens in the second example are optional, you can also `setTimeout { print("hello") }`. Wild.
I'm totally going to end up with a memory leak or something
On a page called "Manual Memory Management"
Oh my word. Oh my fricking word.
I was just casually browsing the Swift source code, as you do, struggling.
=> https://github.com/apple/swift-corelibs-foundation/blame/ee856f110177289af602c4040a996507f7d1b3ce/Tests/Foundation/Tests/TestSocketPort.swift#L83
I see the test data `"I cannot weave"`. Some of you know where this is going, but I did not.
I am easily distracted. So I think to myself, 'that's a new test string, it has a nice ring to it.' So I put it into Google.
It is a line from a poem by Sappho.
Now, if this was a SIBR project or something I would be completely unsurprised. But I lost it: this Apple employe (presumably) is just casually writing very official test cases for this programming language and can't resist letting me know, two years later, that she's gay.
Perhaps the greatest tragedy of my life is that computer programming is the best medium I have found for expressing myself.
=> https://web.archive.org/web/20220121181332/https://aether.exposed/if-they-were-to-cut-open-my-bloated-corpse-they-would-find-nothing-but-cookies
Edit (Nov 7, 2022): updated to archive.org link since the site is down, which pushed us over 140 characters, so now the link is on the lower line

Absolutely quality blog post, highly recommend:
Just bought business cards. I couldn't sleep so I got up to get water. Supposed to get here in October.

In the Blaseball API, there's a field on a Game object called `secretBaserunner`. I don't know why.
People tend to judge artistic mediums on objective grounds. The medium does matter, because an interesting medium attracts or inspires
artists. But that's a subjective quality. One medium is not better than another. The best medium is the most interesting one, and once that medium become boring, it's no longer good, only because it is the same as it used to be.
When you have an idea what you're doing, a strictly-typed language can help you catch errors. When you have no idea what's going on, type
errors are so much less helpful than runtime errors.
I'm sorry Rust libraries, but auto-generated docs that list the types of your values does not count as documentation. Please please write
some documentation. I want a usage example. Is that too much to ask?
(This goes for every other strictly typed language. TypeScript, Java, you don't have documentation either.)
Sometimes, when I have no idea what's going on, I wish that the programming language, would give me a runtime error.
Instead, Rust insists on forcing me to catch every possible error in order to sure that it cannot panic. Well, my code doesn't panic. Instead, it just stops running, exiting silently.
I think what I'm doing is equivalent to wrapping all my code in a `try…catch`. But if I don't do that, I can't compile, because Rust doesn't want me to face any runtime errors.
Ok, I finally got a panic. It contains useful information! `InvalidColumnType(3, "visit_count", Integer)'`.
All I want in my life are bookends. Bookends are one of the greatest inventions of humanity and I don't have any of them.
"I (resident of North America) rarely see kangaroos."
-Some commenter
What does this mean? I think they're trying to make a point, I don't know.
11ty is like 'oh yes we're extremely flexible.' I have some React generated pages and some Gemtext generated pages. 11ty does not support
adding custom template languages. So I can't generate either of them. 11ty is super flexible if you're working with liquid and markdown and js.
Someone created a thoughts page almost exactly like this one, Apr 7th, 2020. I created this page Sep 5th, 2020.
=> https://wesleyac.thoughts.page
The feature parity here is honestly horrifying. I think the biggest difference is probably that they don't have what I call extended text (that's this here). They seem to not have a length limit. I limit to 140 characters in the first line.
I have 1,731 Thoughts, they have 408 thoughts. So I'm clearly better, don't worry. /s
Hello people from Hacker News. Check out the About page understand what's going on here.
lolololololol
People spend a lot of time talking about economic growth, but frequently leave out the context of population growth, which I think would be
relevant. This isn't a thesis yet, merely an observation.
You cannot embedded simplicity inside a complex system.
You cannot embedded a simple system inside a complex system. Your system is only as simple as the most complex part.
I create a lot, but that doesn't stop me from living in fear that what I've created isn't enough.
Am I the only one who thinks node.js is a mess? I guess no one is using node.js? Or something? I don't get it.
I feel like I get more perfectionistic the more tired I get. Like most people get tired and stop caring, but I get tired and lose my ability
to look past things.
I think it is logical to extended the axiom that you shouldn't trust a computer you can't throw out a window to cloud hosting.
If I can't see the computer, I shouldn't trust it.
I'm just so tired.
I want to use Atom. But Microsoft bought Atom so that I would use Visual Studio Code.
I flew into the sky and landed on a cloud. An angel asked me, “are you a real person?” To which I replied, “does the set of all sets contain
itself?”
I fell down through hoops, rings of gold held aloft by eagles. There are few eagles left now. When I rejoined with the earth it was warm. It spread out in all directions. The flea on my monitor cannot hear but can perceive the vast force that oversees all things.
A yellow plane slices through all things. A panic attack overtakes an elder in a small town in a flyover state. The whole world holds its breath for a moment, acknowledging, then moves on with the same pace.
The web is so fricking bad.
I want a 140 character textarea here. Easy, check `.length` client-side; check `len()` server-side. Right?
Wrong!
JS-side `.length` treats new-lines as 1 character, but per some spec, lines in form-encoded requests are `\r\n` delimitated. So Python's `len()` sees two characters.
"Why Do I Choose This for a Living"
Chrome is gaslighting me. Git checkout OJSE from last year, it's broken. Like? I'm pretty sure this code worked at some point, please?
The WHATWG can no more tell me how to make a good website than the government can tell me how to be a good person.
My mouth hurt like hell this time last year, and it hurts like hell now.
It was really bad a couple of days ago. But I still don’t want to talk to people because it’s painful.
People are like, 'docker is so much easier and simpler than a virtual machine.' And then https://apple.stackexchange.com/a/373914
But then again, I cannot for the life of me figure out how to get qemu to do anything, so maybe that's my best bet. (Also going to check out podman…)
It's easy to complain about the Reddit hive-mind, but what really gets me is that Reddit is not a hive mind.
You can have a bunch of people in a conversation, who are all pro-choice, because it's Reddit. And one will be like 'even if unborn babies are people, the mother's body-autonomy takes precedent over the baby's right to live.' And 3 comments later, someone else is explaining how body-autonomy doesn't apply to anti-vaxers because, and I quote, "vaccines are free. Babies are not."
This is not a single, logical, train of thought. I can't understand it.
Frick every time I start thinking about the abortion issue I just end up laughing at Norma McCorvey's Wikipedia page. "She had quit her job at an abortion clinic and had become an advocate…to make abortion illegal." 100% chaotic neutral energy. And I feel bad for her, because I don't think she wanted to be that way. Truly cursed with an interesting life.
God is good!
My soul is asleep. Although my mind should probably be sleep as well. But that’s okay, because God is good.
Gruber thought Markdown would be good because it was readable, but Markdown's real genius is being writeable.
My word, KA really sped up time to connect or something.
Maybe my internet changed, but I used to have to wait like 2 seconds before KA would send anything, and then 6 seconds or whatever for the AJAX graphQL to finish. The second part seems about unchanged, but the first is much quicker.
Editing `/etc/apt/sources.list` again
Man, I don't have these kinds of problems on Arch. (That's not true, I totally do.)
I changed the default font in Vivaldi from Times to Helvetica and it makes sites that don't have CSS look much better
I've been using ssh for years and I learned today that it has escape characters.
Enter/return, then `~`, then `?` to list escape sequences.
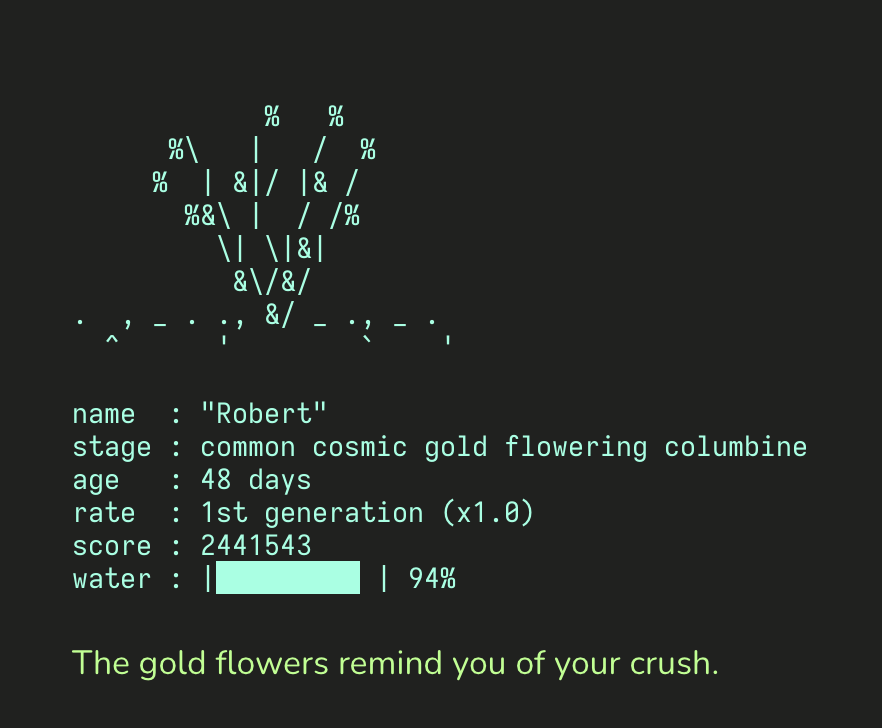
It's so easy to over-complicate Apache config files.
2 ways to do HTTP to HTTPs upgrades
```apache
RewriteEngine on
RewriteCond %{SERVER_NAME} =*.ourjseditor.com [OR]
RewriteCond %{SERVER_NAME} =ourjseditor.com
RewriteRule ^ https://%{SERVER_NAME}%{REQUEST_URI} [END,NE,R=perman
RewriteRule ^ https://ourjseditor.com%{REQUEST_URI} [END,NE,R=perm
```
Or
```
Redirect permanent / "https://ourjseditor.com/"
```
I don't even know what I was doing.
Edit (Sep 13, 2022): These two snippets definitely aren't equivalent and I don't recommend using either of them without understanding them.
What the Long Now Foundation, and a lot of archivists, miss, is that hardware just can’t survive that long.
I bet the Long Now Foundation’s clock fails in my lifetime lolol.
But more directly, there’s no battery with more than a 30 year shelf life, unused. You can’t design a computer that lasts that long.
The key, then, is that batteries are replaceable. I suspect that modular hardware and software is more maintainable and longer lasting than hardware designed to be long-lasting. Or at least, if you want to optimize for long time scales, you should optimize for repairability.
The issue of course, that you need people interested in repairing your stuff. But if people don’t care, then that’s not exactly a fault of the technology.
There's a playlist of kids music that I listened to a lot when I was younger because of one my younger cousins, and I still get songs from
it stuck in my head. "my yellow bus is takin' too long, it's takin' too long my yellow bus…"
The year is 2002
Transcript
The year is 2002. You stand in an empty hallway. The floor is a brown linoleum. The walls, wallpapered, beige, with pink flowers. You walk forward, slowly. It’s difficult to see in the flickering florescent light. At the end of the hallway there’s a door. You try the handle, but find it locked.