Thoughts
With Deno cron, it feels like the rest of the web is finally starting to catch up with features that Dark had years ago ;)
With Vercel Postgres, there's no longer an architectural reason to avoid Vercel, I don't think.
I didn't know that you could deploy WSGI (Django / python) on Vercel. Or Rails it looks like.
I thought you had to use special serverless stuff but I guess that doesn't make any sense.
This guy is running a web server on localhost:91. 91 is a privileged port on Mac; I don't even know what uses that.
Edit: he said he's using SpringBoot.
Welcome traveler.
This is an entry in the Caverns of the Void.
This will be edited with your next stop when it exists.
Every year, millions of students are forced to do homework against their will.
Donate today to help them.
I want to like Matt Parker's videos so much but they're just too long. Show me the math and let me leave, I don't need to see 4 other pieces
of similar math.
I wish I owned a vacuum that was capable of quickly vacuuming a large area and yet was the size of a shoe, a small shoe.

Oh my word I just replied to this email quickly. Like she literally sent it as I was checking my inbox, I spent <30 seconds on a reply, and
she replied back immediately afterwords. I'm in shock because I've never experienced real-time communication over email before. We're speedrunning out here. A, B, A sub < 1 minute.
< adlakm kalmdw klamdklamwd
lakemdlkadlkm awmd amdlk maklwdm awd
wdlkamdl kamllla
lkawdklalkmwdklm
awdlkmlkkkkwmkmkmkmkmwj flnkamwdlkma;ml;m km cvljjk ajldnkjab wdkhab sdghfvybudlhdgutawyjkl,./',;kmnj,a dm
'ajdnajkdnlml,oiuhygkkk kkk kmmoi in ik j jo o iop ikn ii kjboijnjlnljo hilonfnadpa
awlkdnkj a
'a ndjaao a;wdm njkadnjmao dibai dnoaibwdiuksi jnjsijo oandjnawdo;asdjknlknajksdonjknaedio jknjknoij kjajdawduiiokkjnkjanwjdja d;najkdwnajknjasndkjsandnjnaiwjj ij juijwhawdn jaw dnjalwdnoabd kjanh;bf'obhfi'fveoube
oh my word I'm so stressed I have so much built up tension.
Did you know you can just take other people's code off Github and sell it? You don't have to give attribution or follow the terms of the
license at all. Sublime Text has been doing it for years and no one's noticed (until now). (My eye for detail is unmatched.)
I have a love-hate relationship with Sublime Text.
I spend a lot of time in it and I love it. I guess I just wish it was open source.
We tried to do spell checking by giving the spelling checking model more low-level information about the relative position of keys
(especially on mobile, fancy mobile keyboards try to guess where your finger is supposed to be physically). But these models are absolutely blown away by ChatGPT, which doesn't have any low-level information about the position of keys at all, rather, it has tons of high-level information about the types of things that you want to say. I think this represents a kind of fundamental flaw in current/historical approaches to AI and real-world modeling.
Okay so you have to understand I have no musical ability. But I swung at it:
This is me singing layered on:
=> https://www.youtube.com/watch?v=35AiWw4Udr0
=> https://archive.org/details/DCRPS044/Bad+Feeling.mp3
I only spent like 20 minutes in Garage Band making the relative audio levels okayish. But it captures a hint of my vision.
I don't understand why there's not Christian breakcore. My remix of I'll Fly Away is going to be so sick.
(it will never actually happen, don't get your hopes up)
Reddit has decided Rowling is a creep for writing a relationship between Krum (18, so high school senior) and Hermione (15, so sophomore)
Honestly my take away from the criticism of the Harry Potter books is that the vast majority (80%) of adults do not read and have never read children's fiction, and they would be absolutely shocked and blown away if they picked up a random children's book. Harry Potter is nothing. Harry Potter is hypersterilized.
Constance is two years old! It's the whole speedrun to 'it's unethical to put minors in life or death situations'
I had the thought earlier today actually that you can't complain about children doing things in books if their parents aren't present. Like if the genre is kids-doing-things-alone then you can't complain about anything that the kids do. You just can't. They are, for the purposes of the fiction, independent adults because their aren't any real adults in the story. It's like reading Lord of the Flies—it's about kids doing things they shouldn't and 'kids shouldn't do that' is an extremely unhelpful baseline moral argument.
Five Kingdoms opens with a group of 15 year olds getting kidnapped and sold into slavery. I don't know what you want.
Okay this post isn't actually a criticism anymore it's a fun tour of messed-up things that happen in children's books.
Mr. Benedict lies to the children's guardians, de-facto kidnapping them, and sends them into mortal peril. And he's supposed to be the good guy. (And it is thoroughly explored in the book how Mr. Benedict feels guilty about this but believes it to be necessary, and he never coerces the children, he doesn't lie to them, and does everything in his power to keep them safe.)
I can't even start on Rex's *Fat Vampire*. The underage protagonist sexually assaults his girlfriend repeatedly and basically rapes a stranger (and it's a plot point and it's intentional).
Artemis Fowl is committing war crimes at like 12.
The whole premise of *The Unwanteds* is that all the neurodivergent kids are throw into a vat of boiling oil.
Eragon falls in love with a 500 year old elf. (and it's a plot point and she's disgusted by him and they have to work it out and it's awkward)
Criticizing children's fiction for treating children like adults is like criticizing horror movies for being violent. You don't have to like it. If you don't like it, that's fine. But that's the genre.
Do you ever feel like you're sprinting but you're standing still? I'm running through the airport but I feel like I'm not moving.
Apple's spell checking is provided by the open source software project Hunspell. To inform me of my rights regarding this software, Apple
provides the licensing information for Hunspell in `/Library/Documentation/Acknowledgements.rtf`. Okay it's a little buried, but it is there. Sublime Text also uses Hunspell to provide spell checking. They just don't provide the end user licensing information. This is illegal.
OpenAI's whisper runs well locally.
`pip install openai-whisper; whisper --model small.en file.m4a`
Listening to *to love in the 21st century*.
Lyn's iconic.
Of course there's a lot less production and energy than Producer Man unfortunately
Stop Worrying is cool for someone like me who is bad at context switching because it forces context switches, but rarely.
Tab completion is table-stakes. It works in the Python REPL but not in pdb, `interact`. I don't understand.
pdb and ipdb just don't have tab completion and I'm supposed to be fine with this. I don't understand why any uses this AWDUAW*OD language
Honestly it's kind of based to be short any internet provider. In the future they're utilities; only during the dot-com bubble did it really
make sense for cellular carriers to be aggressively running ads.
- I hold stock in a German internet provider for some reason
- Nortel died but why didn't the others
Being a good person is about being joyful, and the more joyful you are the better person you are.
Being a good person is about being miserable, and the more miserable you are the better person you are.
And so instead of defining a function that does something to numbers and then mapping over a list, you just define these functions that work
with lists all the way down.
Working with numpy and friends is hard for me because if you asked me to sum two list of numbers into a new list I would say
oh, let's zip them, then map over the list with `sum`. But if the lists are numpy arrays, you can just add them. I don't think about operators on lists, only on individual elements.
Okay no-phone challenge is harder than I thought.
It's also easier than I thought in some ways. I'm not bored, I just like need 2FA codes.
760 ppm CO2 is not great but I don't know if it's worth opening a window to try to fix it. 67º is just about perfect and I don't want to
ruin it
"If I have the gift of prophecy and can fathom all mysteries and all knowledge, and if I have a faith that can move mountains, but do not
have love, I am nothing."
Racket's macro system is so confusing and bad. Maybe I don't 'get it' but it has none of the things that make writing macros in
elisp/common lisp/matthias's JS lisp interpreter fun. But in Racket it's like fricking Julia out here. It's like they've never heard of an S-expression.
The caverns of the void is going to be extremely hard to pull off because it has to be very interesting while remaining very empty.
I wonder if there's a Python-effect today where programmer who use "ugly" languages like bash, etc, have a greater ability to do things
I think the grand irony is that the only advantage that Package Control has over downloading packages manually is that PC will automatically
update your packages. And yet the biggest problem with PC is that the packages in the repository aren't ever updated.
I love ChatGPT because I can ask it questions. It's easy to find tutorials for this stuff, but if you're following a tutorial and you don't
understand something you have to go down a whole rabbit hole of research.
Can someone explain to me why my head feels so hot? It's 66ºF in my room right now. Will update with CO2 in a sec.
Edit (:18 (I forgot)): 662 ppm
I have so many story ideas that I'm never going to turn into novels and so many game mechanic ideas that I don't have stories for...
Puzzle games with good story are so important and so rare. The puzzle doesn't replace the story.
I'm such an idiot. The entire premise behind modern minimalist is flawed. It's the Long Now clock. I literally said it.
*The Modern Minimalist* is an (unpublished) framework for developing software that operates over long timescales. It tries to answer the question 'how do you design software that is going to still be maintainable in 20 years.' Because there's a weird trend where software that should still function is replaced due to technical obsolesce or lack of maintenance or whatever.
But this is really the same (non-)problem that The Long Now Foundation is trying to solve with their clock. And I mocked them by saying, "The issue of course, that you need people interested in repairing your stuff. But if people don’t care, then that’s not exactly a fault of the technology."
=> https://thoughts.learnerpages.com/?show=27975adb-07d4-4d01-a63c-b1d98e5217d1
I will still probably write Modern Minimalist at some point, because it's really something different. If you want your software to work in 20 years, the best way to do that is creating a company around it and paying someone to rewrite it every 3 years. But that's not what The Modern Minimalist is talking about because that's not "Minimal." It captures the "modern" part but not the "minimal" part. The dream of the Modern Minimalist is being able to write code now that is modern in 20 years while doing the minimal amount of work. But I think there is definitely an aspect of it where you need to ensure that the problem you're solving will still exist in 20 years and that people will still be interested in maintaining your software.
It would be easy to be gaslit by myself or doctors into believing that my throat troubles are a symptom of long-COVID, except for the
picture of myself in the ER with an oxygen mask on in January 2019.
Look the white beauty standard is the people on the cover of *Much Afraid* not the people on magazines. They’re so happy. :D
I'm actually really excited about the potential for current generation AI to close the final 8% of usability on text-to-speech and
speech-to-text.
"Do not be anxious about your life, what you will eat or what you will drink, nor about your body, what you will put on. Is not life more
than food? And the body more than clothing? Look at the birds of the air: they neither sow nor reap nor gather into barns, and yet your heavenly Father feeds them."
> the return on time invested in reading the linked spec is, in my experience, negative on average. That is, reading it actually makes it
> _harder_ to implement the linking spec "correctly".
=> https://lists.w3.org/Archives/Public/public-html/2010Feb/0158.html
I think it's possible that yeah
no
ladybrid
im gone sorry
specs are better now if kling is to be believed
maybe.y4eah
If the defining axiom of rationalism* is that being as rational as possible is better, then it's kind of surprising that it takes like 14
fully rational steps to conclude that computers will eventually supplant humans. It feels like that should be implied from the premise.
*Anyways, I don't know what the "defining axiom of rationalism" is or if it exists.
Also, it's funny that back in 2017 the rationalists were defending against cult-allegations.
Entity with superhuman abilities which I cannot prove exists nonetheless leads me to evangelize that everyone take action now in order to
avoid destruction in a future apocalyptic event.
Unity-learn is emailing me with no way to unsubscribe. All emails from them are now being archived immediately. This is how this works.
I need a supercut of Grian throwing his quartz in, Etho taking the other two items out, and then Skizz saying 'G won fair and square'
Tango et. al were like 'let's make a Ponzi scheme disguised as a charity' but then put the redstone in middle of the room
Watching Tango and then Etho's episode is crazy because Grain tries to rig the heart foundation lottery like 14 times and when they actually
do the lottery Etho rigs it for Grian (accidentally?)
Since we're posting OpenAI theories—I think ChatGPT is a mechanical Turk and there are 8 million employees manually answering every question
I can't believe TCG was this season and it's like not a big deal compared to Decked Out 2. Like I'm sorry Beef. Biggest server wide minigame
I think there a Tumblr post that commented on how school trains us to always look for direction from authority to know what to do next, but
I think it's even more interesting the level to which school equates intelligence and success with ability to follow directions. Ability to follow directions is one type of intelligence but it's possible it's over emphasized.
I didn't realize Impulse and Tango were Zipkrowd back in the day.
Zipkrowd in my mind was for like super technical people, in the way that
Scicraft is today.
We're at 792 ppm CO2 on my desk and 524 next to my window. Which like makes sense except that my desk is 5 feet from the window.
I was worried that leaving my window open was going to increase the amount of pollen/dust/etc in the room, but it seems to have decreased it. PM2.5 and PM10 are both around 5/6.
My CO2 ppm swings widely (like from 600-1000) with small movements of the detector. I need to calibrate it and see if this is an issue or if
it actually just varies that much
Maybe liteworks/TPC makes more sense as a library rather than a stand-alone program. I don't know.
I have been informed by Gitlab that my ssh key has expired.
This is literally so silly I can't wrap my head around it. Like. I have three public SSH keys, https://github.com/matthiasPortzel.keys.
The whole point of SSH keys is that you use the same client SSH key for all servers. Am I supposed to have a special key just for GitLab so that I can rotate just that key on their timeline? Am I supposed to replace that key and change it on all servers?
Password rotation is dumb, but at least it helps prevent password reuse, which is a real problem.
But my SSH key hasn't expired. My SSH key is a file that sits on my computer and it has never left my computer and it has never changed. And it's never left my computer and it's never been hacked.
It's like forcing me to reinstall my operating system or something in order to connect to your website; it's none of your business. I gave you my public key.
Like, git does key signing. If I have commits signed with that key, are they no longer mine because the key has "expired"? Am I supposed add a new key every year and never get rid of the old ones?
It's irrelevant because I don't use Gitlab but yeah. I'm not about to start.
It is important to understand that everyone is terrified all the time. This is not to say that there is nothing to be afraid of (although
there’s not). The solution is not to run at the danger and analyzing the danger only makes the fear worse. The solution is to have fun.
It's funny, I think in JS but I really don't write JS all that often. It's because the JS ecosystem is a mess. I really wish redwood could
save us but they committed hard to graphQL for reasons that I don't understand.
so the thing about stop-worriyng is that it does have a failure mode—namely, sometimes the work still doesn't get finished on time. It's
not magic. What is kind of magic is that those items end up sitting unstarted for less time and you end up making more progress on them than if you were using a different system. I'm getting around to something I said I would do a month ago, but a month isn't that bad all things considered.
I’m considering forking package control and calling it package-control-ff. I think the ff stands for Final Fantasy but I’m not sure.
Simulated annealing is very cool.
It's a relatively simple improvement over the naive case that nonetheless works much better. While it's intuitive why it works, it's not something that you would think of yourself.
Posting this here for my future reference:
> We launched the Supporter badge which is 29.99/yr or 2.99/mo. You can also subscribe to ad-free which is a similar price. Subscribing, and encouraging as many people to also subscribe is the best way to support Tumblr. If you do it on the web we pay less to Apple/Google. Out of the 11.5M monthly active users of Tumblr, only about 27k have subscribed, or about 0.2%. If that were 10 or 20% we could run the site forever.
Tumblr monetization (for search)
Apparently Zed has been publishing releases for months. Very cool editor. Definitely more competitive than something like Lapce
which is having to re-invent keyboard control and UI elements from scratch. It's funny how I can open up an editor and click around and form an opinion within about a minute. I've spent so much time in text editors that my system-1 can pick up on thousands of details about the responsiveness, layout, design, color palette, (false positive) linter errors, keyboard shortcut support, etc. Speaking of responsiveness, Zed already has more key-press-latency than Sublime or a native text-entry field. (Maybe. Always hard to tell when it comes down to milliseconds.)
It's definitely usable. Like.
Startup time is very good, it handled every keyboard shortcut I could throw at it.
I'm sure there would be surprises and missing features as its still 0.111, but since Atom's death if you wanted a GUI text editor on mac that supported command+shift+right arrow selecting to the end of the line, your options were kind of Sublime or VS Code (or XCode, or smaller ones like Xi, or custom configs for vim or emacs, or BBEdit, Pulsar, Textmate, Brackets, others that no one uses) but like that was it. It's very cool to see another big player emerging.
I think I glazed over Zed originally because the collaboration features are a sham. We had Teletype, we have the JetBrains one. I get it. But I don't. It's cool and useful but it's not a 0-to-1 innovation.
They need to not use monospace fonts for their UI elements, it looks like fricking Lunar in here.
Man the nostalgia hit from opening the Atom website archive is the most profound I've ever experienced. I still remember a teacher
mentioning Atom back in 2015 and me opening that website to that color-scheme. "A hackable text editor."
=> https://atom-editor.cc/
Man. Something about that design and color pallet creates this unique world, and yet is so inviting.
I've only written a little bit of Zig, but I think it had a big impact on my coding style. Once I got my mind around them, Zig's structs
combine some of the grouping and encapsulation ideals provided by OOP with some of the functional-programming ideals of immutable objects and functions.
It's really hard to describe because the lines are really blurry, but I think my point is that Zig rests perfectly in the gray area between those things.
In Zig, methods are just name-spaced functions and struct function parameters are immutable. And yet, you can write normal OOP-style code by having your struct methods take a pointer to the struct, which allows them to modify the underlying data freely.

The "rationalists" are a cult that believes that very soon a god-like figure called "superintelligence" will be created, with the power to
solve any problem or to wipe out all of humanity. They believe that the moral imperative of humanity right now is to "solve alignment." If we can do that before the "superintelligence" is created, then we can control it and prevent certain extinction.
The reason I don’t think superintelligence will exist is because I don’t think intelligence is linear. I thought that was pretty clear.
Turing invented the Turing test as a measure of intelligence, and so a computer that was “superintelligent” by this measure would be a computer that passed the Turing test 100% of the time.
Not exactly world-ending scary.
If I don't confuse you it means I'm not trying hard enough.
If I'm trying, I should be doing things that other people wouldn't think of.
It is such a flex that Automattic can reassign the 200 people working on Tumblr to other portions of the business. Like.
Tumblr’s dumping like all of their staff.
I’m kind of surprised this didn’t happen earlier but it’s still disappointing.
This atheist on Tumblr just said “religion will always be illogical and radical”
Yeah baby. “Love your enemies” will always be illogical
and radical. Being personally loved by the God that created the universe will always be illogical and radial. Having faith in something that you cannot see and trusting that there will rewards after death? Illogical and radical.
Like this is scary
=> https://www.statista.com/statistics/1091926/atmospheric-concentration-of-co2-historic/
> Even if the world meets all the national emissions reduction pledges under [2015]’s Paris Agreement—which Trump may axe—we’ll hit an
> atmospheric CO2 concentration of 695 ppm by 2100 [Climate Interactive]. That’s a 300 ppm increase from today’s outdoor levels. If indoor CO2 levels rise by the same amount, we can expect a 16% decrease in average brainpower — for every single person on the planet.
Yikes.
I’m now a CO2 truther BTW. Open your windows and doors!
=> https://medium.com/@joeljean/im-living-in-a-carbon-bubble-literally-b7c391e8ab6
I feel like I missed the day in math class where they explained what the rules for advanced math were.
Like I understand the rules for algebra very well but there are rules for doing higher level math, I assume, but I don't know what they are.
Good morning.
I, on behalf of everyone here in Matthias, would like to apologize for the temporarily lapse in sanity. I would further like to assure you that sanity has been successfully restored. Unfortunately, maintaining sanity is a difficult challenge, and further lapses may occur over the next several weeks and months, which are forecast to include raised stress levels. Rest assured, we have worked diligently to put several safe guards in place in order to ensure that lapses in sanity are brief, and that recovery is swift and efficient. We thank you for your understanding and patience.
I can't do it I can't do it I can't do it. I can't take it I can't do it Oh my word. I can't do it. Ah!
Maybe Linux on the desktop hasn't taken off because the Linux Foundation is investing thousands of dollars into cloud research. The Lima
project, which develops Linux virtual machine interfaces for macOS, is a subset of the Linux Foundation's Cloud Native Computing project.
Because there's corporate support for Linux cloud. There's not cooperate support for Linux on the desktop.
I think the single most important part of a building is the doors. Flimsy doors make the whole building feel flimsy. Heavy doors make the
whole building feel heavy. Doors which are falling off their hinges make the whole building feel like it’s falling apart. The moving pieces are the most important. They’re the areas where the blood is closest to the skin.
Next project I start I’m not going to use version control. There’s no point. (For solo projects before 1.0 release)
One of the things that I love about Etho is that he doesn't assume anything about you, the viewer. "If you've ever worked in the end..."
Like everyone's worked in the End. The game is 10 years old. But it's so much more welcoming and friendly to phrase it that way. Especially over assuming that people know.
Similarly, he frequently reminds us what's going on. 'this is the thing that we built for this reason' and most of his viewers have watched the episode where he built that. Etho's LP is practically a cult, it's not exactly getting new traffic from Trending. But it's about welcoming people, and reminding people, and it's arrogant to assume that everyone has watched your previous videos.
People do that, "as you know..." Well what if I don't know? Then it's like, 'you clearly don't want me here.'
I’m alive. But man my head hurts. I’ve been getting headaches more over after my concussion and I don’t know what I’m supposed to do.
Interestingly, this is also why copy-left software *doesn't* work. It's cheaper to build a clone of the framework than it is to make your
more-complex project open source.
It's like, if company A is charging $100, and then company B makes an equivalent competitor, B should be able to attract company A's
customers at some price that is $100 - the "value" of A's vendor lock-in. The problem is that if A's vendor lock-in is worth more than $100, then B's product has to be free.
Open Source arises out of free market competition when the framework/library is simpler than the application that builds on it. Because then
it's easier to rebuild the framework/library then it is to rebuild the software that exists on top of it.
If you're building a house and your stone supplier increases prices, what do you do? You find a different, cheaper, supplier. If you're being charged a fair amount for a simple software framework; and then prices increase, what do you do? Well, it's easier to create a compatible clone of the simple framework than it is to migrate your complex application to a different framework.
For this reason, it doesn't make any sense to start a project with a non-free framework because the vendor lock-in is so strong. And similarly if a free framework becomes non-free it makes more sense to fork that it does to migrate.
I love the clipping and noise you get from low quality freebie headphones. Music just has so much more texture.
When I was younger I generally followed consequentialist ethics, but in the last 3-4 years I've pivoted to place much more value on whether
an action is good in itself.
One of the big problems for me with utilitarianism is that it doesn't provide a framework to preserve individual rights, especially privacy. Spying on someone 24/7 without their knowledge has zero tangible negative benefit to them, and it may give you some advantage, but that doesn't make it okay.
The two advantages of consequentialism is that it very nicely solves the trolley problem and similar, and that it provides a way to criticize the actions of the negligent but well-intentioned.
The advantage of consequentialism is that it doesn't require "thought-crime" analysis to determine whether an action is good or not. Two people doing the exact same thing can't be "good" and "bad" depending on what they're thinking. Joe and Jill both wake up in the morning and put their gun in their coat, but one is taking a precaution in self-defense and the other fully intends on committing murder. They've taken the same action and that action hasn't yet had any negative consequences and so consequentialism deems them both innocent. And yet, the disadvantage is that it feels like it should be possible to commend murder as soon as the thought of murder occurs.
There are a lot of times in the real world where I'm tempted to take a half-step towards a negative action. For example, watching a friend type in their password and writing it down. Under consequentialism, I should, as it has no negative effects and potential future positive effects. (Obviously, there are counter arguments, to that, some utilitarians would say that that is not optimal. I have considered it, they're wrong. Saving the password is optimal.) And yet, the action itself is, pretty clearly in my mind, wrong. It's not right to steal people's passwords, even if you only use them for good. But again, that's frustrating because I want to maximize the amount of good that I can do.
It may be possible to reconcile these by taking utilitarian approach to maximizing your relationship with all people and with God, instead of just with all people, but that feels ripe for begging the question. For now, I'm still hung up on that privacy point.
Oh I forgot to post it but I came up with a really good Christian argument against pacifism a couple of weeks again.
'They're trying to crush us!'
They're not trying to crush you; they just don't care about crushing you and they're trying to make money.
We are constructing a Tower of Babel and the goal is not to leave people behind, the goal is to get to heaven. Leaving people is just an
unfortunate side effect.
I hate the narrative that big tech or otherwise is trying to prevent you from understanding technology in order to derive you of agency.
This is a Matthias-over-criticism, but big tech is making increasingly complicated technology out of their own hubris and they happen to not care that you can't understand it.
Like Apple doesn't design their own chips in order to prevent you from manufacturing your own compatible replacement silicon. Apple's trying to create the best chips possible and it just so happens that you as an individual can't keep up. (Just so that it's clear, I am responding particularly to the claim that Apple intentionally makes their devices difficult for the *consumer* to understand, but using the absurd hypothetical that you want to try to understand the silicon-level chip. Apple does make their own chips in order to confuse their competition. But we reached the point where computers are too complicated for any one person to understand about 40 years ago.)
Apple doesn't want you replace your own RAM. That is true. But the argument is that they don't want you to understand *something*?
They don't care whether you understand it or not, they just don't want you to do it.
I'm considering creating a meta-framework for software design. Programmers are as likely as anyone to fall into sunk-cost fallacies. And
creating a working solution to hard research problems (self-driving, etc.) is itself a optimization/search problem of the type that humans are bad at solving.
Companies, especially "agile" companies focused on rapid iteration, tend to do something like hill-climbing. Constantly moving uphill keeps your software improving, but only up until you've hit a local maximum.
Maybe modern minimalist will include a recommendation for simulated annealing or something.
I'm guessing there's an assumption that having the logic or state be on the server provides advantages only in the complex case, but I
hypothesize it's the opposite.
That is, if you're update logic is complex, it should be done at the client. If it's simple, it can be done on the server far away from the client. But again, I haven't tested this.
Arguing from first principles, I believe the web paradigm that should win in the long run is "google docs"-style live saving everywhere.
That is, when you open a web form in a web app, the backend creates a "draft" entry in the database and as you type a letter it's persisted to the database. The advantage of this is that it allows you to use the same code flow for editing as for saving. Maybe the draft is discarded after the user closes the page and is not associated with their account; the point isn't to save the draft. The point is that the data is in the only primary data store as soon as possible. Webdev is hell because you have local-storage and the browser page and backend memory and the database, and I feel like a lot of errors arise due to de-sync between these. Additionally, a lot of errors arise due to complexity of re-implementing logic between the front-end and the backend. If you live-steam data to the backend, you can start processing it on the backend instantly and get feedback instantly.
Now, this is different from pure-backend rendering; what you get right now with something like Django or Rails out of the box. The difference is that the visual change needs to be made on the frontend first and then pushed to the server. I'm storing state on the server, but you still need a ton of JS to do the initial update on the client.
I don't know. What's up baby.
The reason this is only a Thought (and not an Idea) is because it doesn't exist yet. I don't think this framework that I'm imagining exists and I've certainly never used it. So I don't know how hard it would be to actually use. Anyways. Good night. Phoenix LiveView sounds close but I haven't used it.
Edit (May 24, 2024): LFSA
Church has changed colors again baby!
Maybe if you find the right hexadecimal values people will start showing up
The logo is still brownish-mauve; but the new admin updated the border to a light blue
I need to make a font.
Possibly based off of my handwriting (for the letter shapes and relative sizes; it wouldn’t be a handwriting-font)
It's interesting, early AJR—"I'm not Famous" being the big example for me—was super punchy the first time you listened to it. Neotheater and
later have a more complex sound which maybe doesn't jump out at you as much, but that set of songs have really grown on me, and I really appreciate that additional depth years later.
I'm really not very excited about TMM but I'll wait until the album drops to give my full run down.
I'm going to start intentionally avoiding "I think" in favor of explicitly disclaiming lack of confidence versus opinion. It's easy to fall
into the habit of using "I think" because you don't want to see overconfident or because you're expressing an opinion, and I still want to disclaim when something is an opinion or when I'm not very confident, but "I think" is a vague and poor way of doing that.
It's a hedge. And I believe hedging is important, but "I think" isn't a good hedge.
Ideas isn't working.
One of the things that I hate is when things get "stale." That's what I'm trying to avoid with Stop Worrying (todo-list items get stale if they sit on your todo list for a while), with The Modern Minimalist (projects get stale if they're not updated), and with Ideas (blog posts get stale). The definition of stale is not "old" and it's not "haven't changed in a while" and it's not "broken." It's basically, "would never be created today." If you report a bug in a project, and that bug would have been fixed if it were reported 1-month into development of the project, but it doesn't get fixed now, then that means the project is stale. It has to do as much with a deviation from the author's intentions as it does with time. With the TODO list, an item on the TODO list is stale if it no longer makes sense for you to do it.
The idea behind Ideas was to un-feature posts when they were stale. The idea being that there shouldn't be anything on my website that I wouldn't say today.
The first problem is that things go stale very slowly. This is why "going stale" is such an insidious problem. You don't wake up one day and decide you suddenly aren't interested in building a bird house. If you did, you could remove it from your TODO list that morning. But your interest fades slowly. So that in 3 months you look at your TODO list and it's winter and there aren't any birds outside and you think "why do I have 'build a bird house' on here."
The second problem, perhaps the bigger problem, is specific to blog posts. The problem is that once I've said something I no longer feel the need to say it again. And so I wrote the Docker post, it got a few hundred comments on Hacker News. And I would NEVER write that post today, because I already wrote it. It doesn't make any sense for me to re-write it and re-submit it. This is the opposite problem from the one that you have in software design: you have code that you would never write today but you keep it around because you've already written it and it's sunk-cost-fallacy.
So my options are to say "hey, blog posts aren't meant to be continuously used/read/referenced, it's fine for them to go stale" or "the only good posts are those that can be continuous used/read/referenced."
I'm leaning towards the second but it still feels unsatisfying.
Maybe knowledge doesn't go stale in the same way, but instead calcifies in a way that allows further thoughts to build on it.
[minutes of thinking here]
I think a lot of what I'm writing down are realizations that I've had that are significant. And realizations by nature become not-realizations after you've understood them and have been thinking about them for years. But it doesn't mean that they're less significant or less important.
For some reason I'm really struggling with an 8am wake up which is absurd because that's been my wake up time for the last couple of months.
But I guess I got off for a couple of days and now my body thinks I sleep from 12am-10am.
Harry Potter discourse on Twitter is actually going to drive me insane.
“The ‘golden snitch’ should be such an embarrassing stain on JK Rowling’s career.”
See, this is what I’ve always said about football. The only people that can possibly score a touchdown on most plays are the quarterbacks and the wide receivers. If you just had everyone go stand in the end zone your chances of catching the ball and scoring would be much higher. Running plays that only get you a couple of yards, 5-10, just don’t matter when a hail-merry can get you 70+ yards and 7 points. Football is an embarrassing stain on American history. You don’t even use your feet why is it called “foot”ball.
I went insane back in '09. Uhhh. Approximately 20–80% of my present pain is tiredness but it's impossible to know how much. Let's see if
it's possible for me to go to bed. It'll be a fun game. "Will Matthias go to bed."
I suspect the answer will be yes because it's too hard to even fight ya know.
yeah
Something about serial killers peaking in the 80s.
=> cdn.vox-cdn.com/uploads/chorus_asset/file/7570225/1_1980s_peakkiller.png
It’s unclear whether serial murders declined because it was truly a fad and societal attitude towards serial killers or something, shifted. Or, if we restructured all of society in order to avoid and prevent vulnerable interactions with strangers.
I think either conclusion is significant.
First of all, I can’t find a source for this supposed “press release.”
Second of all, even if Rowling says “all HP fans agree with me automatically” doesn’t make it true. (What else do you expect her to say?)
Third of all, if Rowling is trying to create a false-dichotomy between Harry Potter fans and people who support trans rights, it’s because she knows that Harry Potter is a *huge* franchise and she wants people to have to choose between supporting Harry Potter and supporting trans rights. She knows that there are a fraction of Harry Potter fans who love Harry Potter but are on the fence about supporting trans rights. Rowling wants those people to choose HP. But those people don’t have to choose one or the other. You can like a 16-year old book series without your present-day beliefs aligning with the author.
Fourth, this post, and posts like it on Tumblr, are going to reach a fraction of the people that the Harry Potter franchise reached. And those people are going to be disproportionately trans people. So you’re going to end up with a bunch of trans people who are chronically online who think that one of the most popular media franchises is a hate-symbol, and millions of Harry Potter fans who have no idea that they’re being offensive.
I guess I’m saying “pick your battles” and I’m not sure reclassifying all of Harry Potter as evil is the battle that trans activists actually want to be fighting. Attack Rowling all you want. Rowling is transphobic. But it seems easier to separate Rowling from Potter than it is to attack Potter and hope it hurts Rowling.
I have a headache and I don't know if its concussion aftermath or if I'm not drinking enough water or if it's stress (I'm stressed) or if
it's because I didn't get enough sleep last night or if it's because I've spent too long staring at a screen.
I should write a post about semantic programming.
Walk through the difference between "halve" and "divide by 2" and "multiply by 50%." and between shuffle and take the top card and pick a random card.
You hate to see it
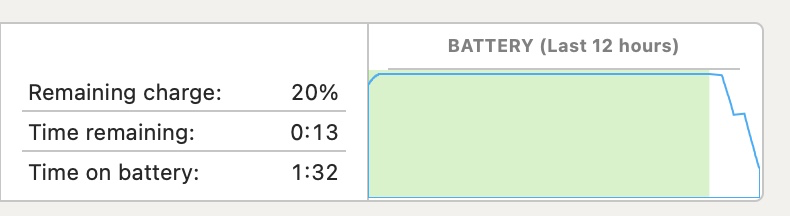
I have like 750 charge cycles on this battery and spotlight is indexing but it's still annoying as heck that I can't make it two (2) hours without being plugged in.
I saw a guy wearing shorts, a t shirt, and a scarf, I love this city.
Okay the guy was me, but sometimes you have to make your own fun.
Why are we here?
“For since the creation of the world God’s invisible qualities—his eternal power and divine nature—have been clearly seen, being understood from what has been made, so that people are without excuse.”
Romans 1:20 NIV
I am doing poorly.
I am not doing well at all.
I am very tired and stressed and unhappy and lonely.
You have to recognize that some people are the types of people that just say things. And it doesn't mean anything they're just saying things
This isn't to excuse them or their words, but it just means you can't literally apply single things that they've said, taken out of context.
I'm talking of course about Rowling. Rowling is transphobic, I'm not arguing that. That's not a single Tweet taken out of context, there's a pattern there. She's made her stance there abundantly clear.
On the other hand, sometimes she just says things.
'Everyone Harry Potter fan agrees with me and is also transphobic'
'Hermione could've actually been black.'
'Hermione and Harry should've ended up together'
'There's one wizard school for all of England'
Yeah anyways.
Note (for myself I guess): when "Disable Cache" is checked in the Dev Tools, Firefox sends `Pragma: no-cache` and
`Cache-Control: no-cache` headers, in addition to disabling the browser's built-in cache. Safari seems not to.
With practice, I wouldn’t downplay a human’s ability to judge speed. Baseball players can time a swing to a fraction of a second, with a
ball moving faster than a car. It’s a little harder to judge acceleration, but most drivers have had practice.
Where I think there’s a lot of uncertainty on the human driver’s part is knowing the size and position of their own car.
(Originally written as an HN comment, but I don’t think it actually adds anything to the conversation.)
This is so funny, there are already anti-anti-AI startups.
https://web.archive.org/web/20231024045157/https://www.paperguard.ai/
Hit my head again and the concussion is back it is so joeover. See you in front of the Wendy’s counter
Okay, so I'm never using flexbox again ever, because Firefox just decides flexbox is too hard and starts randomly screwing with things.
Flight attendant doing the announcements before takeoff (thinks he’s a stand up comedian): “we’re gonna go real fast”
No concussion symptoms so far today. I think drinking water helps with the headaches. Shockingly enough.
;) I’m actually doing fine. What’s great about the Stop Worrying system is that even if you snap at 2pm you still had a good morning and got
6 or however many things done. I washed and folded my laundry and packed. No problem.
I’m super nervous because I’m worried I forgot to pack something and I still have a bunch of stuff I haven’t done, but we’ll see.
Gearing up for a productive day today. I'll edit this with the number of things I manage to get done throughout the day. Current: 8
I have a notification bubble stuck on on both Reddit and Tumblr. a) the web is falling apart b) I’m never going to check my notifications
I’m thinking about, for my next Linux install, just running everything as root.
I don’t think I will because I think it’s a hack over my actual complaints with Linux. Like, my complaint is not that some files are owned by root and some aren’t; my complaint is that it’s unclear which are which. I have some webpages on Luther that are served from /var/www/html and owned by root and some that are served from /home/matthias and are owned by matthias.
I will definitely do something weird with systemd though.
Analysis question: If the count knew that it would take him 16 years to get revenge, would he have still done it?
Yes, absolutely. He
has nothing to live for but revenge. It doesn't matter to him how long it takes, it is his purpose. He sees it as his moral duty.
You can ask me the same thing. If I had known it was going to take 4 years to make OJSE, would I have still done it?
If I know it's going to take more time to fix a bug than the bug will cost people, will I still fix it?
Yes. It's not about me, it's about what the right thing to do is.
I think this is why the count is so appealing even in the face of his flaws; is because his "flaws" are easily written off as him sacrificing for true justice.
When I reread it I need to double-check the timeline, but I'm pretty sure that the count spends 16 years getting revenge on people who put
him in prison for 14 years and that fact lives in my head rent free. Like. "What did it cost?"
It's simultaneously a criticism of everyone else and a criticism of itself.
“Why should the people of our culture choose to use the word ‘live’… and apply it only to a special portion of our lives”
“Why should we accept a world in which eight hours of the day are ‘dead’”
p. 223
“It is a mark of success in a park, public lobby or a porch, when people can come there and fall asleep…Keep the environment filled with ample benches, comfortable places”
p. 458-459
“To lay out paths, first place goals at natural points of interest. Then connect the goals to one another to form the paths.”
p. 588
“If the room contains no window which is a ‘place,’ a person in the room will be torn between two forces:
1. He wants to sit down and be comfortable.
2. He is drawn toward the light.”
p. 834
“The right sill height for a window place, with a comfortable chair, is very low: 12 to 14 inches.”
p. 836
I love this man so much, will edit with the Thought where I say window sills need to be lower. Those last two quotes were from the chapter on window places, Chapter 222 is called “Low Sill” and is on how you need lower fricking window sills.
“One of a window’s most important functions is to put you in touch with the outdoors. If the still is too high, it cuts you off. The ‘right’ height for a ground floor window sill is astonishingly low. Our experiments show that sills which are 13 or 14 inches from the floor are perfect…when you sit down by [most windows] you cannot see the ground right near the window. This is unusually frustrating—you almost have to stand up to get a complete view…On the other hand, glass all the way down to the floor is undesirable…On upper stories the sill height needs to be slightly higher. The sill still needs to be low to see the ground, but it is unsafe if it is to low. A sill height of about 20 inches allows you to see most of the ground, from a chair nearby, and still feel safe.”
p. 1051
This is *A pattern Language* by Christopher Alexander
Re: ADHD and habits: it’s hard to develop habits for things that are difficult or painful, and ADHD makes things difficult.
Adults have this idea that children don't understand responsibility; that they are fundamentally irresponsible. But I don't think that's
true. I think children are not as good at being responsible. I think it's immoral/unethical to give the pressure associated with responsibility to a child. And I think children very rarely have responsibility for those reasons. But I don't think that the child's mind has any more difficulty comprehending responsibility than an adults.
For example, a kindergarten teacher needs to leave the classroom for an hour. They leave one of the students in charge. Now lets say that one of the other children injures themselves.
* The cynic says that this kindergartner doesn't understand being responsible for a classroom, and that the child will not care. The child who is in charge will continue playing with their own toys with apathy towards the other students. I don't think this is true.
* When I say children are not good at being responsible, mean that the child who is in charge doesn't know first aid. Doesn't where the bandages are. Maybe they should have stopped the other child from playing with the scissors before they got injured, but they didn't have the foresight to see that playing with scissors has a high chance of leading to injury.
* It's unethical (and irresponsible) for the teacher to have left another kindergartner in charge of the classroom because if someone got injured, the kindergartner doesn't know first aid. That's not their own fault. And then if another child died or something the kindergartner shouldn't have to live with that on their conscious for the rest of their life.
* yeah rest of this post, I'm going to go lay down and stare at the ceiling, real concussion hours
Is there a term for flirting but you’re like sad. Like you’re just not into it but it’s just kind of happening. Yeah.
Couple weeks late on the color theme update, but as the leaves are changing outside, Thoughts has changed to a nice (obnoxious) red.
(This is the American Animals light theme.)
"And you killed the Author of life! whom God raised from the dead, and to this we are witnesses!"
-Acts 3:15 ESV
One of the interesting things about software development is that it is just as often plagued by the opposite of bike-shedding: it's
impossible to build a bike shed because one maintainer has to sign off on all PRs and they're distracted with the nuclear reactor core.
Why is Rober just re-making a Veritasium video from 4 years ago. Is science Youtube a cult? Is it controlled by the Mormon church?
Down to the *exact same* stock footage of a bending part of a satellite, and a shot of Howell holding his textbook and saying that it's the most cited book on compliant mechanisms. Like, okay, the same stock footage is easy to explain: the BYU team has a presskit. Similarly, talking to Howell makes sense, if he likes being in Youtube videos and invites them to come visit. But that still doesn't explain why both videos watch like ads for BYU or why Rober felt the need to make the video in the first place.
Identical stock footage:
https://youtu.be/97t7Xj_iBv0?t=6
https://youtu.be/9c2NqlUWZfo?t=323
Parallel scenes of talking to Howell holding his book, talking about how it's the most cited book while also maintaining that Howell is humble:
https://youtu.be/97t7Xj_iBv0?t=40
https://youtu.be/9c2NqlUWZfo?t=205
I can handle a lot of bad takes on the internet but Harry Potter criticism is going to drive me insane.
The criticism is literally that Rowling is “too good” at writing discriminatory characters.
‘The racism in the hp universe is never meaningfully addressed.’
The only thing I can think is “have you read another book?” Followed by “have you actually read Harry Potter?”
Like.
I think there’s this implicit idea on Twitter or whatever that racism is worse than violence. Because I can name 50 villains, screw it, I can name 50 “good guys” who commit more atrocious acts of violence than Voldemort. The things that Dahl villains do to children make the cruciatus curse look kind. Ender straight up kills a guy.
But Voldemort uses a slur and that makes Rowling racist.
What is your opinion on *To Kill a Mockingbird*?, because Lee is significantly better at writing racist characters than Rowling.
Voldemort (or Malfoy for that matter) isn’t a super deep, fleshed-out, character, when you consider that it’s a 7-book series. If you want to criticize Rowling’s villains, it’s that they’re too shallow.
Well, and this is the kicker for me. The narrative is *never* so much as even sympathetic to Voldemort. I don’t think there’s a single scene where Voldemort is nice to someone. I’m trying to think, in the flashback to Slughorn’s party, does Riddle like give a gift to one of his friends? I don’t think so, I think he gives a gift to Slughorn to butter him up. And I think Rowling writes at one point that ‘Riddle didn’t see his friends as friends.’
If you told me I had to write an essay about how the villain is actually in the right, I don’t think I would, in a million years, choose to write it about Harry Potter.
I feel bad but it's like my stomach hurting and I don't know if it's concussion related or not.
I listened to the first 8 episodes of *Welcome to Night Vale* and I still don’t know if there’s a plot. That’s a bad thing.
Adiamente’s unique in that it looks very libertarian but is actually pretty authoritarian.
Actually yeah, thinking about it more, it’s kind of an authoritarian fantasy.
It glorifies the sacrifice of being a dictator, which appears to be a more libertarian position (dictator is bad, people shouldn’t want to be dictator), but that’s also the official position of many dictators.
Working around my executive dysfunction is so funny. Like I can't put the dirty clothes on my floor away, sorry.
I can’t tell if I feel bad because I have a concussion, because I ate only junk food today, or because I took a 3 hour nap earlier.
It's weirdly difficult for me to read comics. Like my brain doesn't have practice looking at still individual frames and inferring action.
I'm super cynical and not trusting towards other people. It's something that I really need to be better about. It's the source of both my
social anxiety and also a lot of my difficulty forming relationships.
The cohost dynamic is super weird to me because it feels less like a platform and more like a single community.
It makes me wonder if this dichotomy is inherit to social media and if it makes them hard to monetize.
I think the perfect goal would be that the CEO has an account and uses the site a lot, but no one knows who they are.
The fact that there is any beauty in the world is a miracle. The fact that there is any goodness inside humans is a miracle. God is good.
I've like totally placeboed myself into believing that any aberration of feeling is a result of hitting my head last night.
I'm a totally different person!
Slipped and hit my head on the grass earlier. I might have a light concussion which is frustrating.
Not to imply that Dumas doesn't think that revenge is awesome. Like I at least get an element of "oh my word the count is so cool" because
he's possibly the most dedicated to revenge of any character in fiction, but Dumas doesn't shy away from portraying the downsides of that dedication either. (Or maybe he does, and that's why we see so little of Edmond in the book.)
Regardless of other points, I can’t take anyone who views the Israeli-Palistine conflict as a colonizer/indigenous people conflict seriously
The Israeli people are similar to colonizers in the way that they have taken resources from other places and have used them to fight a war that has driven Palestinian people out of a region that they have historically occupied.
But it is very different in that a) the Israeli and Jewish people also have been living in the disputed area for literally 1,000s of years and b) the Israeli people are not a “colony” of any other country. During the colonial period, European would actually enter into areas where they had never historically lived and create colonies that were actually an extension of the country that they originated from.
And it’s really unnecessarily reductive to equate those things. I recognize that it’s a rhetorical tool, but I think it’s also indicative of a tendency to appeal to historical right and wrong as a substitute for evaluating the actions of current events for their own sake.
This reminds me of my criticism of shallow literature analysis. There’s a tendency when reading fiction literature to ‘figure out’ what each element in the book represents in real life. And it looks like that same tendency extends to trying to ‘figure out’ what each element of a modern day conflict maps to in a historical conflict. And first of all, the mapping is never that clean, there’s always additional nuance. And second of all, that assumes that the thing that you’re comparing to is a solved problem without nuance itself.
And so I think that it’s a rhetorical tool, but I also think there are people that really think that Israel is a “colony” because it’s more comfortable for them to just assign familiar labels to unique scenarios and then stop thinking about it. For these people, what they mean when they say “Israel is a colonizer” is that they have the same opinion on Israel as they do on European colonies during colonial times. And I think they should put in the thought to come up with a different opinion for it because it is not the same.
Studies reveal I am still Matthias.
Can I please go to sleep now.
Hmmm. Yes, I’ll allow it. Goodnight.
Okay here’s the deal.
I’m a tiny fragment of a person.
See when I don’t exist I can just wait until I exist again but right now I do exist just in a tiny little sliver. Like this |
That’s me: |
Yeah.
Okay.
So circles fall from the ceiling onto my face and they slither off me. Sometimes.
Dreams can come true.
My problem with git is that diffing and etc are line-based. It means it can't be used for binary and text-serialized data. When the
fundamental commit model would work fine with other types of data. But diffing, merging, etc, really only works with text source code.
I'm so stressed this is awful. I haven't been timeblocking for a couple of days now and I'm falling apart.
What Xisuma doesn't understand is that you can clickbait me with a thumbnail with Etho in it once, but then I'm going to click "Don't
recommend this channel" and I'm never going to see another video of yours. But sure, tell me more about how clickbait thumbnails get you more views.
Planning Center finally updated to fix the bug where clicking the "preview file" button also downloads a copy of the file.
My faith comes from my and humanity's very evident need to be good in the face of a world that is incredibly lacking in goodness.
I wouldn't go so far to say that my faith is unconditional, but it's not conditional on other people's faith or on scientific evidence.
“Men of Israel, why do you wonder at this, or why do you stare at us, as though by our own power or piety we have made him walk?”
“The greatest single cause of atheism in the world today is Christians: who acknowledge Jesus with their lips, walk out the door, and deny
Him by their lifestyle. That is what an unbelieving world simply finds unbelievable.”
Hey, that's not a bad definition of "highly opinionated"—"your opinions have a strong influence on your views, leading to a weak
correlation between popularity and your view on it." Assuming that most people's opinions on something not very correlated with it's popularity, which obviously isn't true.
Using ChatGPT for music recommendations. Other sources have either a ton of recency-bias or have difficulty understanding how far outside
of the genre you're willing to go.
And the major downside is that it's going to have a ton of popularity bias, but that's not necessarily bad since popularity is often correlated with quality (unless you're highly opinionated, which I'm not about music).
Edit (:29): the other disadvantage is that is recommends music that is just wrong.
The problem is that if I don't feel like writing I'm not going to feel like writing a ChatGPT prompt.
I think when people say “human extinction” they mean “like a lot of people dying.”
I don’t think even a worst-case analysis of a nuclear war leads to human extinction. Like. I actually don’t think that “Trump could also lead to human extinction.”
I don’t know, I haven’t run the simulations. I don’t know what technology the government is hiding from us. Maybe the US has enough nukes to blanket the entire planet.
I hate Twitter so much. Like seriously.
‘We shouldn’t panic about this in particular, lots of things could lead to human extinction’ isn’t the nuanced, moderate view that you seem to think it is.
Consiracy thoery: microsoft did a study that says yhat waitinf an hour before playing vieos games make 5y3m more fun and the y created the
whoe fake download screen for updates when you want to play.
Man I am being assaulted by a desire to write lisp but there's no point. Like.
This is why I should be using emacs. I could always screw with an elisp config if I had one.
AI generated maps for video games or ttrpgs actually seems like a viable use-case. You want a castle with a bunch of non-empty rooms, etc.
Maybe a linear progression is the wrong metaphor. Maybe it’s more accurate to talk about how different areas experience technological
revolution. Then it’s easy to say that technological progress will slow down in the current areas, (and this is pretty non-controversial, even the most adamant tech-bro would admit that the most innovation in the smartphone already happened and the current changes are less drastic), while simultaneously arguing that there are still plenty of areas to revolutionize.
I need to create a post that summarizes my thoughts on the future. We live in an interesting time. Technological progress has been
happening rapidly for decades and it’s simultaneously absurd to argue it will slow down starting tomorrow and to argue that it will continue forever.
I hate Tumblr because I’m like “here’s a great drawing of a character I really like. But they’re a little different, that’s weird.” Well,
its because the artist is drawing the version of the character that exists in their HermitCraft x Detroit: Become Human crossover fan fiction comic.
(I love fan fiction authors. I’m just not ready for it, you know.)
I stayed up past my bedtime finishing *Adiamante*. It’s very good at something but I’m not sure what.
There’s a narrative that ADHD people have trouble forming habits. I don’t believe it.
I could make this argument in a couple of different ways.
The simplest is this: ADHD correlates with a number of symptoms that do it make it difficult to form habits.
Also, self-destructive, reoccurring, actions, such as those to which ADHD people are prone, can become habits in themselves.
That is to say, I (who may or may not have ADHD), got in a habit of not doing my laundry. (That is, I would try to do laundry every other week, think to myself ‘I hope I can complete the laundry this week’ and then I very very rarely did.) Then I created the Stop Worrying system, starting doing laundry twice as often (half the load size) and I starting getting laundry done.
(I also changed my definition of “successfully getting laundry done” so there is some amount of goal-post-moving in there, but that’s part of the Stop Worrying system—how to be happy with what you can get done.)
I honestly don’t understand why Mojang keeps adding mobs from real life to Minecraft.
Like.
They’re messing with parts of the game that I just don’t care about.
I’m thinking about whether or not it’s a good thing that the internet now assumes everyone is malicious.
It's crazy how Etho is getting more views on his multi-hour Decked Out run uploads than he was on normal Hermitcraft videos.
Maybe the user wanted a derived cache of message history *on his own computer* in order to search with ripgrep.
Man EU politics are a mess.
The president like isn’t elected. Because they’re still trying to pretend that the EU isn’t a single entity. So they just like pick someone. Worse than the electoral college for sure.
Why is it "I do" but "it does."
"I walk" "it walks"
I thought that was a plural thing.
"The cat walks" "the cats walk"
The best way to explain my social anxiety, aside from the normal things, is that it feels like I’m having to speak a different language.
It's kind of so nice using Ghost because I want a page with a downloadable file, and I can just do it, without writing any code.
The eating-lunch-together-doomers:
> Everyone has lunch at the same time so it’s crowded as heck and we get even more mortal danger.
"It has no SMELL!"
"And electronic air!"
=> https://www.youtube.com/watch?v=A6Wy_pWscsk Stadia Launch trailer YT
=> https://cohost.org/GoogleStadia/post/3015664-cloud-gaming-is-elec Cohost post that originally pointed out how fun this was
This is me reading the actual script of an actual ad that Google actually released for Stadia. (I cut the boring parts.)
Transcript
Stadia is only the newest, most logic-defying / mind-bending / absurd gaming platform on earth! Forget BOXES! Forget CONSOLES! Just your GAMES! your SCREENS! And ELECTRIC AIR
and this ELECTRIC AIR is...
STADIA
Unlike consoles, Stadia doesn't take up ANY space. it makes no NOISE! It has no SMELL!
Stadia has the games you're looking for!
With Stadia you can GO virtually anywhere. Live any WHEN. Play with ANYWHO.
Stadia is GAMING for FREE RANGE HUMANS.
Stadia travels ACROSS screens.
No DOWNLOADS. No UPDATES. No WAITING. Stadia bends TIME and SPACE to take you STRAIGHT to your game. So Stadia's a PENCIL.
Stadia is so impossibly mind-bending, so free to move from screen-to-screen. So not dependent on DOWNLOADS or UPDATES. It's like nothing you've ever played games on BEFORE.
UNTHINK THE THINGS YOU THINK ARE THINGS. Free your mind.
STADIA!
The crazy thing is that it takes like an hour to clean your floor and make a TODO list, and that's kind of a required prerequisite to being
productive. That's one of the things that the Stop Worrying system allows for that many productivity systems don't.
One of the problems with “we’re screwed” as a narrative is that it’s very easy to support for different reasons.
You’ve got your AI-doomers, your climate-doomers, your conspiracy-theory doomers, your COVID-doomers, your car-doomers, your immigrant-doomers, your technology-doomers.
The thing that *The Boxcar Children* absolutely nailed was that as a kid fantasies of independence are valuable because of the agency and
the freedom. I think too many kids books recognize that freedom-from-parents is an important trope, but then they over-commit to it. They treat it as "how do we get the parents out of the way." And I think it hurts them. I think it is a weakness of e.g. Lockwood & co. or Fablehaven or whatever that the kids have living parents that they just don't care about. As a kid, the real dream is living in a boxcar in the backyard of someone who loves you.
Color Theory honestly like bops. Like relaxing, interesting, immersive, music.
=> https://music.apple.com/us/artist/color-theory/5043122 Apple Music
=> https://colortheory.bandcamp.com/ Bandcamp
Start with The Majesty of Our Broken Past obviously but it's all pretty good.
They hate me they hate me they hate me i hate this im so sad and aahaahahahhakmlkmklmlmlmlknmkl;nmkkkmmklklmlkkllk button ijnoknm,,,,,n
400 tabs on my phone. I’m going to reinstall the OS in the next couple weeks hopefully. Clean them up.
Giggling about ‘text files searched with ripgrep’ again. This commenter has elevated the Discord engineering team to super-geniuses in my
mind, by comparison.
For me, the predestination/free-will question is answered like so: humans have free-will and agency, but we don't have any power or merit.
We can screw around and make our own decisions down on Earth during our life time and some of those decisions are better than others, but there's only one decision that matters and that's allowing God save us. God takes complete responsibility for our salvation, we just let him in the door.
The distinction that I make that is very different from the distinction that Calvinists make, is that my inclination would be that even saved Christians don't have any meaningful power or merit.
The only thing that I want to keep, that I want to take into heaven, is my faith in God. When God redeems the Earth he will destroy all sinful things and if that includes everything I've ever made and every relationship I've ever had I would be okay with that. And I shouldn't be, maybe, but God won't. God will redeem many things and many relationships.
I don't understand systemd unit files at all. (has written several systemd unit files from scratch.) I don't know.
This mailing list is choked up on non-ASCII characters in this guy's name. It's 2023 and HN is advocating moving *to* this technology.
This whole big-O-notation thing is actually a big deal. Just rewrote a program keeping it in mind and it's so much faster.
I went from
# O(n) node insert
# O(n) node removal
# O(1) lookup
# O(1) popping (removing and returning the lowest score)
to
# O(log(n)) node insert
# O(1) node removal
# O(1) lookup
# O(1) popping (removing and returning the lowest score)
and the program is so much faster. I can't even say it's 10x faster or anything because it's no comparison. Like it's infinitely faster for large enough n.
No here's how I can compare them: After running the slow version for 42.8 seconds it spent 42.1 seconds in node-insertion and processed 17,745 nodes. After running the fast version for 42.2 seconds it spent 4.795 seconds doing node insertion and processed 1,045,985 nodes.
So that's a 58x increase in the number of nodes processed. The current bottleneck is all the operations on the individual nodes.
I want to write code but I have all this dumb writing to do.
Like actually I've invented 4 or 5 projects at this point that just involve me writing a couple hundred words.
“people who don't watch etho regularly think he's like this super competent intimidating guy but his true appeal is that he's all that and
also really really lame”
Like Etho references Seinfeld and no one who watches Etho has seen Seinfeld but they just roll with it because it’s Etho.
Next time that I need to write a strictly typed programming language I’m going to put in the four hours of up-front work to configure an IDE
the way I like and see if that makes the language more bearable.
Why is there a CSS framework called Pure CSS. Like. "Pure css" means you're not using a css framework.
In kindergarten we had a bookshelf of bins of books. And the bins were labeled A-Z and the books classified into a bin based on how
difficult they were to read. So A was just a couple words on the page, Dr. Seuss might have been around an M or an N, and then at the end there was a big bin with the last letters of the alphabet. I don’t remember any of the exact letters, but this last bin might have been W-Z. And it contained all of the books that weren’t picture books: the novels. (Okay we were in kindergarten, novella would probably be more accurate, but whatever.)
Now I was a very good reader as a kindergartner. Some of my classmates were in the A-D range all through kindergarten, but I read almost all of the Q, R, S, T books. But I was scared of that last bin that had novels.
Now, the pictures (or lack thereof) had nothing to do with it. By the time you’re reading U books there are way more words than pictures anyways. What scared me was the length. When you’re reading a picture book, it’s quick to read it from start to finish, no big deal, a couple of minutes. But my fear with the novels was that I wasn’t going to finish it, and I was going to have to come back to it later.
This fear isn’t rational, strictly speaking. But at the same time, it is very scary. To venture into a book knowing that you might get interrupted, and then you might get lost. You might lose your place, you might forget what happened at the beginning, you might get stuck and be unable to make it to the end. This does happen to me now, I have to force myself to finish books that I don’t want to, and there are books that I never finished that haunt me. I’m scared of losing my place in a book.
I eventually read all the interesting picture books and had to start on the novellas, and it was fine. I was reading Harry Potter by third grade.
But this story should tell you a lot about me. I’m still terrified of commitment and of not finishing things and of losing my place in the world. I got over the initial hump with reading; I let go of the edge of the pool; I’ve made computer programs that have taken so long that I’ve lost motivation in the middle and given up. But there are other areas where I’ve never really committed to it. I’ve never sat down to try to draw something that’s going to take more than 30 minutes. I’ve never asked a girl out. I’ve never written something longer than 4,000 words. Maybe someday I’ll have the courage to reach into that Q-Z bin in these areas.
Yeah I’m not moving. I think it’s possible I’m not a real person. How did this happen to me? What’s next? Why
Yeah
Function that takes `["123", "456", "789"]` and needs to return `[1, 2, 3, 4, 5, 6, 7, 8, 9]`
Python:
`list(map(int, list("".join(strings))))`
Ruby
`strings.join.chars.map &:to_i`
The Ruby is just so much more readable to me. We're joining into one string, taking chars, then converting each char to a number. It's a chain of operations from left to right.
To read the Python, we start at the `""` in the middle, then read to the right, then jump to the list call, then go to the very beginning and read the `map(int`.
Edit: 1:12: needed an extra `list()` around the Python, I got an error.
Edit: 23-11-25: You could also do the Python as `from itertools import chain; list(map(int, chain.from_iterable(strings)))` which may or may not be easier to read. In which case the Ruby is `strings.map(&:chars).flatten.map &:to_i`.
Edit: 24-10-28: Simplified the last Ruby example; updated examples for consistency.
The commonality of au pairs in the US today at first seems like a sketchy practice from the 1700s but it’s like, fine.
I love the XKCD-sucks blog because he's like "xkcd is no longer a great webcomic (though it once was)" and he's claiming it went downhill
around comic 700.
And I think you could argue those comics are not great.
But there are a lot of comics that we would consider classic, great, XKCDs from around 900-1200.
Like this post is an XKCD-915-moment.
The complaint that encapsulates most of my frustration with strictly typed languages is that I cannot open a REPL and enter some expression
that allows me to check what the compiler thinks the type of a variable is.
Maybe strictly typed languages are only usable with an LSP and editor where you can hover over something and see what type it is (is that a thing?).

Last night, laying awake in bed, "I need to watch less YouTube." Today, Etho uploads a two hour supercut of his Decked Out runs!
Honestly the AI bros sound delusional to me. There isn’t going to be another AI breakthrough. It’s not going to happen. There’s a 0% chance
Siri wipes out humanity, there’s a 0% chance ChatGPT wipes out humanity, and there’s a 0% chance whatever neural network OpenAI creates in 2030 is going to wipe out humanity.
It has no reason to. It has no ability to.
"Unfortunately, you don't get to decide what qualifies a notification as "Time Sensitive," that's up to the app developers."
Oh my word I hate despise hate the "feature" that puts the words "TIME SENSITIVE" above all notifications. It's not time sensitive. I have
no time sensitive notifications. I have very carefully organized my entire life so that I have no time sensitive responsibilities because they stress me out. Please leave me alone. Hpel
HN on Fandom: ”Going to that website in regular ol' chrome without an adblocker was an experience indeed. I had no idea.”
I never would have guessed that there's a form of degeneracy where you create too many prediction markets, but I should never
underestimate the devil.
Just so we're clear, I think it is objectively hilarious that the one advantage of ChatGPT (it being easy to use) has already been written
off by its biggest proponents in favor of "cheat sheets" with information printed so densely that it is completely illegible.


When selecting a date in the Reminders app it will give you three options ("Today", "Tomorrow", "Next Weekend") or "Custom."
It bothers me. Wednesday is not a "custom" date. It's a day in the future. I'm not "customizing" the reminder by scheduling it for the date that it needs to be on. The whole point of this app is assigning dates to items. "Tomorrow" is not a custom date but "wednesday" is.
It’s kind of infuriating to me that the most widely accessible climate change information continually uses Celsius.
I’m walking past some climate change posters outside in America that talk about 1.5-2°C of temperature change and I don’t understand who the target audience is.
As someone who is socially awkward, I cannot for the life of me tell where normal people draw the line between socially awkward and creepy.
I err on the side of not-creepy, so it’s fine, but it kind of stresses me out that I don’t know where the line is.
Neotheater is an all-time album.
It's the AJR that I'm going back and listening to.
"I gotta go so much bigger so they can never shut me down"
"I gotta go so much bigger so everybody’s proud of me"
"And if this is my final album and if I am forgotten, I hope I made you smile, that's all I ever wanted."
One of the things that's so cool about Into the Spiderverse is that is appreciates the beauty of movement in comics.
I don't think this was something that was originally unique to Spiderman. I have some old Hulk comics and Hulk is constantly jumping over buildings or mountains, and then of course half a dozen super heroes can fly.
But it's just so hard to get the special effects right for big movement scenes in live action so it's something that's kind of faded from the genre.
Slower shipping options used to be cheaper because they would send it across the country in a slower truck or whatever, but the logistics
chain is so efficient now that I bought something off Amazon with 1-week shipping; they didn’t ship it for a week, and it arrived the same day that they finally shipped it.
That’s not to imply that the cheaper shipping is a scam, I’m sure there are advantages on Amazon’s side to having a week of flexility around when to ship my package, but it’s funny that travel time is a negligible part of the equation (in this specific case).
There are 5,000 packages on package control. They're like 'oh it's so hard to migrate to Python 3.8.'
I bet that if you took all packages on package control, filtered out all themes, all color schemes, all syntax files, and then sorted by number of lines of Python code, there would be a few outliers at the top with a few thousand lines of code, but I bet you that all of the packages below the top ten would have a combined total of less than 10,000 lines of code.
And the kicker. What changed between Python 3.3 and Python 3.8? Anything? Like Python doesn't want to break backwards compatibility either.
The absolute arrogance of the Goodread reviewer who gives *Emma* 4 stars. (It's me.) Eh, the beginning moved very slowly.
“She will give you all of the minute particulars which only women’s language can make interesting. In our communications we deal only in the
great.”
It's easy to forget that when I posted Terra Magma no one cared. It wasn't until I posted it on the advertise your programs page that
it got any momentum.
Stop Worrying is so long! I didn't realize this when I was writing it, but at 3,800 words it might be the longest thing I've ever written.
It's twice as long as the About page here, and barely longer than the longest paper I wrote for school (~3,000 words).
It doesn't feel that long? I guess because it has an intro and then 4 sections, and none of the sections are that long. It could definitely be 500 words shorter. It could also be 500 words longer. What I really don't know is if it needs to be anywhere near this long at all, or if the concluding/summary 4 bullet points could stand on their own for example. I get the feeling that couldn't. For example, I've heard many people say "do things as soon as possible" but I've never heard anyone else describe the TODO-list system that I use.
Edit (2025-1-28): The novel I started in 2016 is up to 6,000 words, so that’s technically longer.
“And that you should have been so mistaken, is amazing!”
-*Emma*
It’s the comma that does it for me. Wow
Matrix doesn't support search. I'm dying.
All the comments are like, 'we've only had a couple times when encryption keys stopped working randomly' and 'it's really easy to-self host a Sliding Sync proxy. It's just a Dockerfile and reverse proxy.'
The problem with writing about the state of ads on the internet is that it has always been pretty bad. I remember waiting through adfly
links to download minecraft maps years ago.
Are scientists sure they counted right? 400,000 seems like a lot. Maybe it's like dogs where there are a bunch of different breeds.
There’s dramatic irony (drama derived from the reader knowing something they characters do not) in The Count, but unlike in sitcoms or soap
operas, the real conflict is much larger than the characters could guess, as opposed to much smaller. The former is interesting to me, the latter is frustrating.
(I’ve been reading Emma. You can tell because it effects my prose.)
Really not a fan of Linux's design choices. The line between user and root is so difficult to cross and yet needs to be crossed so often.
I’m bored and lonely. It’s so easy and yet so hard
“I have no fear of drowning, it’s the breathing that’s taking all this work.”
It's just so weird to publish writing.
It doesn't feel real.
The ideas are real and I want to share them, and the words are a medium to do that, but then the words form a document which can be judged separately from the ideas.
In 2019 Luke said it was the game of decade, but the game is stronger than ever 4 years later. If the game has limits, we haven't found them
Autumn. Peace falls over the scene. There is a finite past and infinite future. There is nothing behind and everything before. Joy. The LORD
of peace is present in the stones.
I want to explore. I want to imagine. I want to believe and imagine and believe and feel. And I want to find and to know.
There’s an exchange in a book where two characters are sparing with wooden swords. One guy slips past the other man’s guard and is about to
hit him when the other man brings his left hand up and catches the sword with his palm. The first man kind of hurrumphs and says ‘where I’m from, we teach people to always treat practice swords as real swords.’ And the man who caught the swords says, ‘where I’m from, we teach people to tell the difference between a practice sword and a real sword.’
Okay so 10/10 quip, but I think there’s a useful distinction being made here. “Always follow best practices” sounds good, but it should never come at the cost of understanding why the practice exists or when it is *actually* needed.
Of course the real punchline in the book is when the second guy says ‘I can do it with real swords too’ and shows a scar down the middle of the palm of his left hand.
I don’t remember the book. It might have been the Queen’s Thief series or that other one that always confuse it with (false prince or something).
Edit :18: I think the book is The Runaway King, the sequel to The False Prince. It can’t be The Queen’s Thief because the guy gets his hand cut off in like book 1.
I joked that OJSE was three months away from completion for 4 years. Reruns has been one day away from completion for a year.
Honestly, Apache's kind of a mess. It sucks that a config error in one virtual host means that Apache can't start. VirtualHosts should be
isolated from each other and instead they're like all concatenated together into the same config file which is read sequentially (and they can like leak variables and stuff because the Apache config file syntax obviously doesn't support variable scoping).
I want all of the fame and none of the hate, I want all of the love and none of the pain.
I want all of the stuff and none of the space, all
of the beauty and none of the vanity. Perfection.
"Some folks are living mostly off-grid using solar power & each heavy application is chewing thru their limited batteries"
Tell me more about these open-source contributors who can't contribute to Bun because they live off grid and they don't have enough solar power stored up in their batteries to run Discord.
"Some folks..." you have invented a whole person who does not actually exist.
Thinking about the Discord Ripgrep comment again.
At risk of deconstructing the humor,
It's absurd to me for 3 reasons.
1. rg and Elasticsearch do different things. They're not comparable. You would have to build a layer to move messages from the DB to files so that you could use rg, then build an API to expose the result of rg to the client.
2. rg is O(n). Discord has billions of messages. You could obviously chunk them by server and time and build an index but like. That's what Ellastisearch does.
3. The sheer scale. I just I can't. I You can't put like. Even if you did 1 and 2 and built this cursed index-adaption layer for storing messages in plaintext files and indexing them, like. You're at risk of like. You can't put that many files on a hard drive. You have to build a distributed replication layer.
Like, building 1, 2, and 3 from scratch is so hard that you might as well re-build ripgrep while you're at it.
=> https://thoughts.learnerpages.com/?show=acafe37f-063e-4276-8373-58a9d0d7a1af
Reading Norma McCorvey’s Wikipedia page again.
=> https://en.m.wikipedia.org/wiki/Norma_McCorvey
Etho's that kid that messes up the punchline of the joke and accidentally tells a funnier joke and everyone thinks it's intentional.
Some of the MatthiasPortzel.com source is up now
=> https://tildegit.org/matthias/matthiasportzel.com/
You have to be able to love every individual person and you have to be able to see the individual in groups of people.
Really, those are things that you need for people to like your business. There’s a weak correlation between people liking your business and
it being successful
There are three things you need for a successful business:
* good
* different
* character
The product needs to be good. It doesn’t need to be amazing, it doesn’t even need to be better than your competitors, but it needs to be good.
It needs to be different. Not so different that it’s incomparable, but different enough that there are situations where people would want your product in particular.
It needs to have character. This is the business, “different” referred to the product. There has to be a story or an environment or something that people can hold in their minds so that they think about it.
I don't know if I've ever mentioned this, but you can git clone WhisperMaPhone from https://thoughts.learnerpages.com/WhisperMaPhone. Not
sure when I set that up.
"I liked the point about how Chat GPT 'frequently hallucinates information' to come up with an answer for the user. I've never heard it
phrased that way"
=> https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence)
I hate this. I need to chill the frick out but my heart is racing and there's nothing going on. 94 bpm
Manifold is fun because the people on there are dumb but I can just bet against them. I’ve bet no in like 20 different “will AI…” markets.
If you didn't know what Decked Out 2 was I could show you a picture of the outside and tell you that Tango had been working on it for about
a year, and you'd go, 'yeah that tracks. I couldn't build a building that impressive in a year.'
I really hope that in 10 years someone makes a documentary about Blaseball. I need other people to appreciate how hard we went.
I love the Stop Worrying system so much because I am very much not mentally stable. I have done nothing today but laundry. But! I have done
laundry! And washed my sheets! And folded and put away everything! And that's such a win compared to 2020 Matthias that it makes me really happy.
It's not about doing everything or doing everything at once, it's about just keeping moving.
I feel like part of the strong push toward strictly typed languages is a new generation of programmers whose priority is getting a job.
Obviously this doesn't make any sense but that's what I feel like.
For me, the entire joy of programming is in being able to type the code and see the result. And so I don't understand why people are flocking to strictly typed languages that introduce an additional step between writing the code and seeing the result, unless they're not programming for the joy of it. (Which, also, possibly, is the case.)
Game Changer has etched itself into my brain. I saw a Tumblr post about James Spader and my first thought was, "from the Spader toaster"
Rewatch is at the point where it's usable and I've started using it today. I need to change some text in a couple places, then throw it up
on Luther.
I'm not sure what to do with it though because I'm probably never going to polish it, but I am going to use and I kind of want other people to use it.
I could spend all day just filing bugs in Sublime packages. It would be easy. It would be fun. It would drive me insane.
Have you heard the good news?
Jesus Christ who had died has come back to life and now sits at the right hand of the Father.
Good morning.
Rewatch is so close to finished. I want to finish it but I also have to cope with the fact that it’s a dumb idea.
Like, congrats, I’ve created a, uh, website that lets you look at a YouTube playlist given a YouTube playlist url.
Add 1 month to a date in Python:
"There's an inherent ambiguity in adding a 'month' to a time"
Add 1 month to a date in Rails:
`+ 1.month`
I'm going insane I'm going insane I'm going insane. It's not ambiguous. Fricking figure it out. The reason I use high level languages with robust standard libraries is so that I don't have to implement date handling logic myself! I get it. One month isn't a fixed number of milliseconds, but newsflash, neither is "a day". Like. Any human being understand what I mean.
Okay there is a third-party Python module for this. It's okay.
```rb
MacBookGamma:~ | matthias% irb
irb(main):001:0> require "active_support/all"
=> true
irb(main):002:0> Date.today + 1.month
=> Wed, 11 Oct 2023
```
The reason I don't buy the whole "Python won vs Ruby because it's simpler" argument is because Python has complex features like generator
functions that absolutely get used and that I absolutely do not know how to use. `.send :func_name` is non-trivial, right, but it's not more complicated than a generator function or a list comprehension or other Python features that Ruby doesn't have.
"And I would add: NEVER use ":" or "/" in any file names. It is too confusing"
Seems pretty simple to me.
Oh Lord, what are you going to do with me? (broke down trying to walk into church (too many people))
Bash script pro tip; every script should start with:
```bash
#!/bin/bash
(
cd $(dirname "$0")
# rest of script here ...
)
```
Then, if you want to spawn multiple processes, you can include `trap 'kill 0' SIGINT` after the `cd`.
This gives you a more reliable and encapsulated environment to work in. Otherwise how you invoke the script tends to matter more.
Then Jesus opened their minds to understand the Scriptures. He also said to them, “This is what is written:
The Messiah will suffer and rise from the dead the third day, and repentance for forgiveness of sins will be proclaimed in his name to all the nations, beginning at Jerusalem. You are witnesses of these things. And look, I am sending you what my Father promised. As for you, stay in the city until you are empowered from on high.”
I can't take TinkerCad seriously because there's a Minecraft button in the upper right, and clicking on it turns your design into a
Minecraft world.
Called Schwab ‘cause their email is all
> If you have any questions, please call us at 1-800-435-4000, 24 hours a day, 7 days a week.
They hit me with the “our office is currently closed, please call back within normal business hours” and hung up. Yeah.
palette/pallet may be the most annoying homophone. Neither of those words is common enough that they need to overlap pronunciation.
Today in ‘HN criticizes Discord’:
> users are the product (data collected and upselling Nitro)
That is not what “users are the product” means. Oh my word. “users are the product…upselling” holy cow.
Edit (Sep 17, yes I'm obsessed): From the same comment: "[Discord]’s also subject to US sanctions or internal bans where entire countries can be blocked"
ESbuild parses typescript by copy-pasting large chunks of the official compiler.
=> https://github.com/evanw/esbuild/blob/cc74cd0f50bc58b768b24685e2440316266e2fac/internal/js_parser/ts_parser.go#L1106
Probably copyright infringement, it's fine.
This is amazing, re-Typescript parsing
> ...MS wanted to submit a proposal for type annotation syntax in core JS. The actual proposal differed from TS syntax in several key ways because TS's actual syntax is a) horrifying, b) incompatible with JavaScript's, and c) to this day fully understood by not one single human being. Thankfully the TC39 committee shot it down.
> The worst part is that “to this day fully understood by not one single human being” is not an exaggeration. I've been over to the TS Discord to talk with actual Microsoft peeps about some of the syntax corner cases. Their response is that I should read the parser source code to see what it does. It's all procedural to them; no one over there is thinking about the grammar in abstract formal terms. And when they tried to do so for the TC39 proposal they gave up and submitted a modified version because the real one is basically intractable. As far as I can tell, there is exactly one thing in all the universe that knows how to parse TypeScript, and that is the official TypeScript parser. Everything else that needs to deal with TS syntax just uses the full MS parser if it can. The closest thing there is to a robust third-party implementation is the Sublime TypeScript package. (VSCode's TS syntax highlighting relies on LSP to work, which just uses MS's TS parser.)
-Thom1729 on Discord.
This is the thing, they're like, "We can't break backwards compatibility, because these packages aren't being maintained, and so they
can't update." But the packages aren't being maintained in the first place! So the packages all have bugs.
And then there's this whole thing about how all sublime packages have standardized on Python 3.3 and they can't update because it would
break the packages, but there are a bunch of other compatibility issues and stuff arising from the fact that they're using an old version of python.
It's just crazy to me the extent to which Sublime Text users want to pretend like everything is fine and dandy and there's nothing wrong
with the ecosystem. Like if you suggest using a LSP or tree-sitter they get super defensive and insist that the built-in packages are perfect. And then someone points a super obvious major bug in the default packages and they're like, 'Well um, that's a hard problem and you can't expect us to solve it.'
Developing a perfect syntax highlighting system for every programming language would be extremely hard for the Sublime staff to do. I don't know why they can't build LSP or tree-sitter into the editor and then use syntax definitions or language server implementations from VSCode or other editors.
But when I suggest that I got the replies:
> If you have specific dissatisfaction with a built-in syntax, file a bug on GitHub.
> All syntaxes written against latest ST syntax features, are (IMHO) quite complete and performant.
And I do have issues but my issues are the same issues that every one else is having. Like look at the number of referenced issues on this bug:
=> https://github.com/sublimehq/Packages/issues/2267
It breaks go-to-symbol; it's not a good bug.
Edit, the JS/TS syntax package volunteer maintainer on this issue:
> I think I've taken a couple of stabs at fixing it, but it turned into a huge pain (basically due to https://github.com/sublimehq/sublime_text/issues/3494, if I recall)
So there you have it, from the maintainer of one of the most complicated and most thorough default packages, Sublime's syntax highlighting system is inherently difficult to work with.
*ding*
*One Way or Another by Blondie*
*The elevator door opens fully to reveal me sprawled face down on the floor*
Self-hosted LLM are not quite ready.
`codellama:7b-python` runs on my laptop, but outputs mostly gibberish.
I hate Python so much but everyone else in the world is too lazy to learn Ruby because it's "too confusing" to have any quality of life
features whatsoever.
"Boring humans are the failure point."
-A [dead] HN comment
The sentiment was that the limiting factor to interesting content on the internet is humans' willingness to seek out and distribute that content.
Of course, the actual content of the message was promoting malware? Or something?
My pastor argued on Sunday that breaking an unjust law is just, but it is also just to be punished for breaking that law.
I wish that it were possible to turn myself off and on again. I feel like actions that I am about to take are different from the actions
that a neutral, freshly rebooted, Matthias, would take.
The Count of Monte Cristo takes place in a French society that had just invented the guillotine, an execution tool that we regard today as
barbaric and brutal. The Count’s response to the guillotine:
> “do you think the reparation that society gives you is sufficient when it interposes the knife of the guillotine between the base of the occiput and the trapezal muscles of the murderer, and allows him who has caused us years of moral sufferings to escape with a few moments of physical pain?”
Later they witness an execution by mace (mazzatello):
> the mace fell on his left temple. A dull and heavy sound was heard, and the man dropped like an ox on his face, and then turned over on his back. The executioner let fall his mace, drew his knife, and with one stroke opened his throat, and mounting on his stomach, stamped violently on it with his feet. At every stroke a jet of blood sprang from the wound.
> This time Franz could contain himself no longer, but sank, half fainting, into a seat. Albert, with his eyes closed, was standing grasping the window-curtains. The count was erect and triumphant, like the Avenging Angel!
Yeah…
Somehow people read that and go, “this guy’s got some good ideas.”
So this may be me reading my own view into the book, but my impression of The Count of Monte Cristo is that Dumas is criticizing the French
justice system for the exact opposite reason that The Count (the character) criticizes it. That Dumas is satirizing the Frenchman who looks at the justice system and calls for it to be more brutal, by creating The Count, a character who is brutalized at the hands of the French Justice system and responds by saying, ‘this justice system could never be brutal enough for me.’
I love how since no one says "respectfully" in normal conversation, "respectfully" has come to mean "disrespectfully" or maybe "I'm
behaving respectfully even though I don't want to."
The problem with the "adding something to the TODO list so that you can check it off" is that there's a sense of accomplishment with
checking it off, when under Matthias's Stop Worrying productivity system, there shouldn't be. The sense of accomplishment should come from following the routine. You should feel accomplishment the entire time you're working, not just when it's finished.
This is important because sometimes there are times when you need to check something off that isn't done; e.g. it's no longer actionable or no longer important. If your goal is completing things and you feel good about removing something from the TODO list because it's complete, then you feel guilty about removing something from the TODO list because it's unimportant and you don't have time for it. But you shouldn't, it's unimportant! You should feel good about not-doing that, because it means you have more time to do other things.
The chants were some of the best things to come out of Blaseball. “No eyes, eleven hearts, can’t lose!” “Ban ground” “Kath Math!”
Breakcore isn't enough, I need a script that automatically switches between playing breakcore and my music library like musical edging.
It's funny how breakcore artists create this super chaotic music out of anger* and then I listen to it out of boredom.
*Obviously I don't know exactly how they artist was feeling, but the song name is "[expletive] THIS [expletive] [expletive] #BOMBGRL" so I'm guessing the author wasn't happy, which is kind of weird because I'm happy listening to the music. I'm chilling.
For some reason the electric scooter rental companies decided that their ideal use case was young people commuting (with a helmet, on the
road), when it really should have been as a mobility aid to help people with difficulty walking travel a couple of blocks.
Scooters compete with walking. Why would you use a scooter instead of walking? The scooter companies answered that with "it's faster." This doesn't work for two reasons. First, you only plan on walking if it's a short distance. Second, finding, unlocking, and parking the scooter takes time.
Instead, the scooter companies should have answered the question "why not walk?" with "it's easier." Immediately, you're not renting scooters, you're renting chairs with wheels. Your target audience is people who are too lazy (or tired or old or whatever) to walk. This is great because they suddenly rely on your product. You're enabling them to move around and be active in the city when they couldn't be otherwise. This is an established solution; think of electric carts in the grocery store or the cart in the airport that gives rides to people with difficulty walking. And some of your users are older people, but it's also people who are drunk, pregnant, not physically fit, injured, obese, carrying a heavy load, etc. And notice, *none of those people can use an electric scooter.*
The only people that can use electric scooters are people that don't need them.
"There's no speed limit" is from this article with the same name.
=> https://sive.rs/kimo
"the system is designed so anyone can keep up"
If you're not keeping up, it's not because you're too slow; something's wrong.
I got 9 hours of sleep last night, why do I feel like I need to lie on a polished slab of marble and be steamrolled.
This girl just stopped and asked me what I was working on on a Saturday night. I just stared at her. They don’t get it.
I've created entire games and programs and essays that are more better than most people could ever do and I haven't released them.
That was probably my biggest take-away from Terra Magma. There's no such thing as concentrating quality too densely. Create something then in six months tear it down and rebuild it keeping only the best parts. Most people don't have the patience to build something the first time.

{kind=link}
Okay here's the plan. I have no friends and nothing to do. I'm bored and tired. I'm going to go do 10 pull ups.
"Against you only have I sinned and done what is evil in your sight, so you may be justified in your words and blameless in your judgment."
-Pslam 51:4
I wish parkour was more culturally similar to rock climbing.
I’ve tried to describe what I mean like 4 times and it keeps slipping away from me. I think because I do really like parkour.
The current technology landscape is hell. Joined a Slack and my email address was automatically given to an "AI notetaker bot" company who
signed me up for 8 mailing lists.
I was going to say I want to live long enough to outlast the clock, but honestly I don’t think the clock will ever get built.
The Long Now Clock is going to fail because no one is going to visit it because they buried it in the middle of the desert.